/stɪl/ n. an apparatus used to distill my ideas from raw to refined.
Blogmarks
Abstraction, intuition, and the “monad tutorial fallacy”
https://byorgey.wordpress.com/2009/01/12/abstraction-intuition-and-the-monad-tutorial-fallacy/The process of learning is more essential than the insight or abstraction that we encounter on the other end.
What I term the “monad tutorial fallacy,” then, consists in failing to recognize the critical role that struggling through fundamental details plays in the building of intuition. This, I suspect, is also one of the things that separates good teachers from poor ones. If you ever find yourself frustrated and astounded that someone else does not grasp a concept as easily and intuitively as you do, even after you clearly explain your intuition to them (“look, it’s really quite simple,” you say…) then you are suffering from the monad tutorial fallacy.
This last sentence feels really important as someone who likes teaching. I’ve found myself frustrated at times trying to teach something that now feels obvious to me. Of course, I’ve had the chance to struggle through to the light bulb moment.
How can my teaching be grounded in presenting learners with an effective learning path instead of a destination?
I came across this post via Justin Jaffary’s post on Divergent Histories.
write for one person
https://wizardzines.com/comics/write-for-one-person/don't get tricked by the writing demon, write for 1 person instead of for everyone
Instead, I picture a specific person and I just write for them. Often this person is "me, but 3 years ago" or a good friend.
This was on my radar thanks to Simon Willison's RSS feed.
Water-use for data centers versus almonds
https://bsky.app/profile/mtsw.bsky.social/post/3mo22c3iirs2e"2.5 billion gallons" sounds like a lot but is about 2 tenths of 1% of the amount of water (approx 5 million acre-feet per year) used to grow almonds just in California.
This is in response to a report from Amazon that their global data-center operations withdrew 2.5 billion gallons of water in 2025.
Related: The AI Water Issue is Fake
Ruby for "shell scripting"
https://ratfactor.com/cards/ruby-shell-scriptsRuby is a really good Unix citizen and I think it’s woefully underused as a general-purpose "scripting" language.
This article is a nice background and introduction to using Ruby for scripting. I've always felt that small, expressive scripts are one of Ruby's strong suits. When I need a personal one-off script to automate a set of steps, I almost always reach for Ruby.
Here is a fun tidbit:
I think this ancestral timeline may be interesting:
1977 AWK by Aho, Weinberger, and Kernighan
1987 Perl by Larry Wall
1995 Ruby by Yukihiro Matsumoto
I had no idea that awk was so named because it is the initials of the creators.
awesome-python: An opinionated list of Python frameworks, libraries, tools, and resources
https://github.com/vinta/awesome-pythonThere are a ton of awesome-<thing> lists out there on GitHub. What stuck out to me about this one is both the breadth and the depth. This is a massive repo that covers a ton of different areas and each one is broken down into a ton of subcategories. Furthermore, it is the #10 all-time highest starred repo on GitHub.
Goblins, gremlins, and raccoons. Oh my!
https://bsky.app/profile/emollick.bsky.social/post/3mkjwmbebr22pExcerpt of a recent addition to the Codex for GPT-5.5 system prompt:
Never talk about goblins, gremlins, raccoons, trolls, ogres, pigeons, or other animals or creatures unless it is absolutely and unambiguously relevant to the user’s query.
Project Glasswing: Securing critical software for the AI era
https://www.anthropic.com/glasswingMythos Preview has already found thousands of high-severity vulnerabilities, including some in every major operating system and web browser. Given the rate of AI progress, it will not be long before such capabilities proliferate, potentially beyond actors who are committed to deploying them safely. The fallout—for economies, public safety, and national security—could be severe. Project Glasswing is an urgent attempt to put these capabilities to work for defensive purposes.
The People Do Not Yearn For Automation
https://www.theverge.com/podcast/917029/software-brain-ai-backlash-databases-automationThis article makes the case that AI doesn't have a marketing problem. Rather the AI companies are pushing "solutions" that people don't want into every system that they use day-to-day.
And so the tech industry is rushing forward to put AI everywhere at enormous cost — energy, emissions, manufacturing capacity, the ability to buy RAM — and locked into the narrow framework of software brain without realizing they are also asking people to be fundamentally less human. They then sit around wondering why everyone hates them.
This article talks about "Software Brain" a bunch which is a precursor (or precondition) of "AI Psychosis". If you think of everything in terms of how it can be flattened into software systems, then it's a short step to start thinking about how you can use AI all the time to 10x and automate all of that.
Reflections on Writing for 20 Years
https://www.scotthyoung.com/blog/2026/04/08/20-years/It's an incredible feat to have been blogging for so many years, to have done it so consistently, and to have it all still out there for the world.
I've had a blog for the better part of the last 15 years, but there have been various iterations of it that no longer exist anywhere on the public internet. In fact, I'm not even sure I could find the static site generator repos where some of those lived.
The metamorphosis of the internet means the path I took to get here literally doesn’t exist anymore. Back then, a nobody with a personal website could rank for top search engine terms, webcam footage could go viral on YouTube, and the hot thing for gaining subscribers was something called a “blog carnival.”
While there are a lot of benefits to blogging -- e.g. refining your own ideas and documenting your expertise -- it is tempting to think that putting out interesting articles could hockey stick your audience and, by proxy, your career. Unfortunately, that's trying to play a game that hasn't existed for a while.
After twenty years, I think my only advice is to write the kind of stuff you like to read. That way, you’ll know you’ll reach an audience of at least one person.
I feel conflicted about statements like this because there is probably some truth to it. At the same time it's a bit dismissive when you're trying to have an impact and build enough of an audience to be part of The Conversation™.
Quoting David Szymanski
https://bsky.app/profile/en.sitnik.es/post/3mj3g74fkfc2tOne of the most frightening things I’ve ever heard is when someone pointed out that the existence of the uncanny valley implies that at some point there was an evolutionary reason to be afraid of something that looked human but wasn’t.
Spooky!
Amara's Law
https://www.computer.org/publications/tech-news/trends/amaras-law-and-tech-futureWe tend to overestimate the effect of a technology in the short run and underestimate the effect in the long run.
Quoting Hillel Wayne
https://bsky.app/profile/hillelwayne.com/post/3miwlxjeurk2eIn general, work that shortens feedback loops is the most valuable "metaproject" work that can be done on a project. Doesn't matter what feedback loop: testing, compiling, deploying, getting customer feedback, analyzing data, whatever
Best Paper Awards in Computer Science
https://jeffhuang.com/best_paper_awards/Collection of best paper awards for 32 computer science conferences since 1996
I imagine this was a ton of work to dig through all of these conference websites from the past 20 years to find and link to the papers that won best paper awards. This isn't the kind of data that is all just sitting behind a open REST API somewhere.
It's neat to see conferences that I attended or submitted to like ICSE as well as ones that were outside of my field of research, but are now areas of interest like AAAI.
Also, this is exactly the kind of resource I was looking for when I asked on Reddit recently: Most important LLM paper in the past year : r/LLMDevs.
Rent a phone number
There are a bunch of services out there that will temporarily rent you a phone number either for a one-off verification or for a limited amount of time:
Let AI Interview You
Addy Osmani shares the idea to “let AI interview you”:
I’m about to start a project. Interview me until you have 95% confidence about what I actually want - not what I think I should want.
This is similar to Matt Pocock’s “Grill Me” Claude Code skill:
Interview the user relentlessly about a plan or design until reaching shared understanding, resolving each branch of the decision tree. Use when user wants to stress-test a plan, get grilled on their design, or mentions "grill me".
Quoting Jerome Powell
https://open.spotify.com/episode/6LIiHWax5flkn2jYVKlYAe?si=yPw-Fd-NTNuQOzwmNyq7HA&t=1660&ct=1510At the end of the program in this episode of the Marketplace podcast, Kai Ryssdal quotes Jerome Powell (the current Fed chair):
Confidence is what you feel before you really understand the problem.
Your job isn't programming
https://codeandcake.dev/posts/2025-12-12-your-job-isnt-programmingGreat explanation of what makes a good abstraction:
Remember: abstractions are ideas, so a good abstraction should change the way you think about part of your codebase. If you introduce an abstraction and it doesn’t change the way you think, you haven’t made an abstraction, you’ve made a layer of indirection.
The Fargo Drill
https://drdavepoolinfo.com/resource_files/fargo_sheet.pdfThis is a neat drill (and game) that you can do solo or with a group of two or more. The basic premise is that you break a rack of 15 balls and play called shot pool starting in random order (like with straight pool) and then at any point during your turn you can flip the game to rotation order where you now have to play the lowest ball on the table.
In the first phase of the game, each potted ball is worth 1 point. In the second phase of the game, each potted ball is worth 2 points.
I learned about The Fargo Drill from this reddit comment.
The 2025 AI Engineering Reading List
https://www.latent.space/p/2025-papersThe people at latent.space have curated a list of ~50 papers across ten areas for AI engineers looking to dig into relevant research in the AI and LLM space in 2025.
Here we curate “required reads” for the AI engineer. Our design goals are:
- pick ~50 papers (~one1 a week for a year), optional extras. Arbitrary constraint.
- tell you why this paper matters instead of just name drop without helpful context
- be very practical for the AI Engineer; no time wasted on Attention is All You Need, bc 1) everyone else already starts there, 2) most won’t really need it at work
Funny to see that they completely side-step "Attention is All You Need". As foundational as that paper is, they consider it old news and not practical for engineers in 2025.
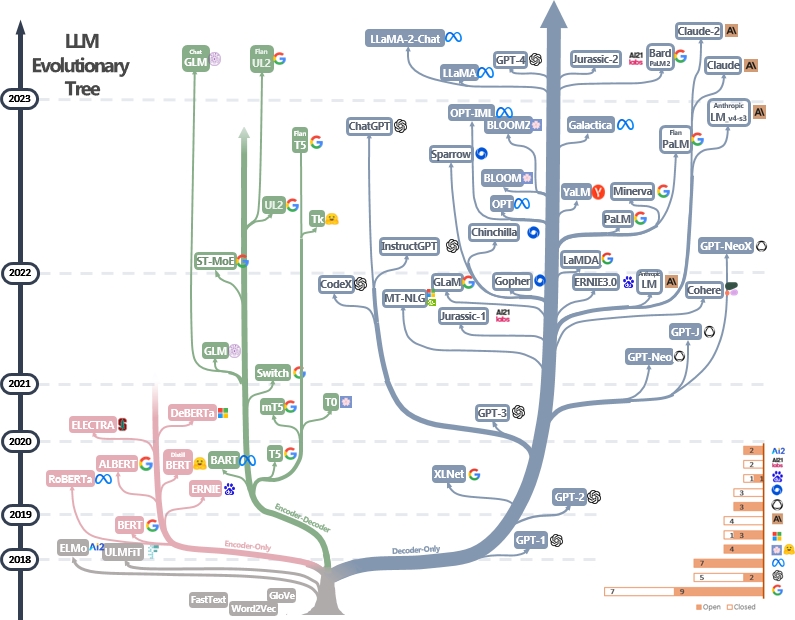
There is a repo LLM Practical Guide full of papers and an "LLM Tree" diagram that may have been a partial source of inspiration for the latent.space paper clubs. Unfortunately, this repo hasn't been updated since 2023. That said, there are still a lot of good resources in there.
This "LLM Tree" diagram is excellent showing the different branches of LLM tooling over time.
Nobody knows how the whole system works
https://surfingcomplexity.blog/2026/02/08/nobody-knows-how-the-whole-system-works/Understanding a (complex) system wholly is a fantasy. We might pride ourselves in having a strong grip on how a whole stack of things work, but there are always layers of abstraction that we are relying, that we’d be lost without.
This is the fundamental nature of complex technologies: our knowledge of these systems will always be partial, at best. Yes, AI will make this situation worse. But it’s a situation that we’ve been in for a long time.
Potential interview tip embedded in this post — often an interviewer is looking for more than the “correct” answer to their question. They want to see your thought process or how you respond when you reach something like the edge of your understanding.
I remember talking to Brendan Gregg about how he conducted technical interviews, back when we both worked at Netflix. He told me that he was interested in identifying the limits of a candidate’s knowledge, and how they reacted when they reached that limit. So, he’d keep asking deeper questions about their area of knowledge until they reached a point where they didn’t know anymore. And then he’d see whether they would actually admit “I don’t know the answer to that”, or whether they would bluff. He knew that nobody understood the system all of the way down.
Shell Tricks That Actually Make Life Easier (And Save Your Sanity)
https://blog.hofstede.it/shell-tricks-that-actually-make-life-easier-and-save-your-sanity/The shell is a toolbox, not an obstacle course. You don’t need to memorize all of these today. Pick just one trick, force it into your daily habits for a week, and then pick another. Stop letting the terminal push you around, and start rearranging the furniture. It’s your house now.
This post is jam packed with useful stuff it took me years to pick up. Plenty of new-to-me things that I’m looking forward to integrating into my workflows.
I've been thinking about what things I would add if I were writing my own version of this article:
<command>-- include a space in front of a command to exclude it from shell historyfc-- edit the last commandcommand <some alias>-- ignore the alias (e.g. I havecataliased tobat, but maybe I actually want to runcat)
Unsolved problem in computer science
https://bsky.app/profile/tef.bsky.social/post/3mhnwnb3xl22runsolved problems in computer science: copying a file from one computer to another
AI Psychosis
I'm seeing the term "AI Psychosis" pop up all over the place right now. Here are just a few places:
From Kill Chain, by Kevin Baker:
This obsession with Claude is a kind of AI psychosis, though not of the kind we normally talk about, and it afflicts critics and opponents of the technology as fiercely as it does its boosters. You do not have to use a language model to let it organize your attention or distort your thinking.
From a recent interview with Andrej Karpathy:
I kind of feel like I was in this perpetual, I still am often in this state of AI psychosis, just like all the time, because there was a huge unlock in what you can achieve as a person, as an individual, right? ... And so there's like a lot of new things. I want to be at the forefront of it, you know, and I'm very antsy that I'm not at the forefront of it. And I see lots of people on Twitter doing all kinds of things and they all sound like really good ideas. And I need to be at the forefront or I feel extremely nervous. And so I guess I'm just in the psychosis of like what's possible, like because it's unexplored fundamentally.
From Jasmine Sun's claude code psychosis:
I dubbed this phase my “Claude Code psychosis,” though some argue “mania” is the better term. It’s addictive to express a vision and see it instantly appear, getting into the build/test/iterate loop at an electrifying rate. There’s an apt joke that Claude Code is GPT-4o for nerds: it reflects your desires and makes them real, providing the rush of creation with minimal sweat.
Patricia Clarke compares the “Glass Delusion” to what is happening now with AI, also using the term “AI Psychosis”.
Aaron Levie (CEO of Box) posted the following on X which I pulled from Tech CEOs Are Apparently Suffering From AI Psychosis:
CEOs are uniquely prone to AI psychosis because they’re sufficiently distant from the last mile of work that still has to happen to generate most value with AI
Centaurs and Cyborgs on the Jagged Frontier
https://www.oneusefulthing.org/p/centaurs-and-cyborgs-on-the-jaggedAI is weird, there is no instruction manual
AI is weird. No one actually knows the full range of capabilities of the most advanced Large Language Models, like GPT-4. No one really knows the best ways to use them, or the conditions under which they fail. There is no instruction manual. On some tasks AI is immensely powerful, and on others it fails completely or subtly. And, unless you use AI a lot, you won’t know which is which.
Here are observations of lower-performers going from no-AI to using AI:
We also found something else interesting, an effect that is increasingly apparent in other studies of AI: it works as a skill leveler. The consultants who scored the worst when we assessed them at the start of the experiment had the biggest jump in their performance, 43%, when they got to use AI. The top consultants still got a boost, but less of one.
I’m not sure “skill leveler” is the right term here. Something like “speed-booster” or “efficiency enhancer” seems more apt to me. When I think about programmers using LLMs and agent harnesses, they aren’t usually writing a new level of code, but rather producing a similar quality of code at much faster speeds.
This paragraph from Mollick’s book “Co-Intelligence” sums up these concepts well:
Using Al as a co-intelligence, as I did while writing is where Al is the most valuable. Figure out a way to do this yourself if you can. As a starting point, follow the first principle (invite AI to everything) until you start to learn the shape of the Jagged Frontier in your work. This will let you know what the Al can do and what it can't. Then start working like a Centaur. Give the tasks that you hate but can easily check (like writing meaningless reports or low-priority emails) to the AI and see whether it improves your life. You will likely start to transition naturally into Cyborg usage, as you find the Al indispensable in overcoming small barriers and helping with tricky tasks. At that point, you have found a co-intelligence.
Ruby on Rails Edition of the Superpowers skills repo
https://github.com/lucianghinda/superpowers-rubyA Ruby on Rails–focused fork of obra/superpowers — a complete software development workflow for coding agents built on composable "skills".
I learned about this from Lucian Ghinda’s Linkedin post.
Coding Is Now a Skill Issue: Andrej Karpathy on Agents and AI Psychosis
https://www.youtube.com/watch?v=kwSVtQ7dziUThis is the November 2025 Inflection:
I would say in December is when it really just something flipped, where I kind of went from 80/20 of like, you know, to like 20/80 of writing code by myself versus just delegating to agents. And I don't even think it's 20/80 by now. I think it's a lot more than that. I don't think I've typed like a line of code probably since December, basically, which is like an extremely large change.
I've also included a larger excerpt from the interview because I think there are some other interesting comments alongside that one line. For instance, naming this "AI Psychosis" characterized by constantly thinking about working with more and more agents and keeping up with the latest capabilities in the AI space.
I kind of feel like I was in this perpetual, I still am often in this state of AI psychosis, just like all the time, because there was a huge unlock in what you can achieve as a person, as an individual, right? Because you were bottlenecked by, you know, your typing speed and so on. But now with these agents, it really, I would say in December is when it really just something flipped, where I kind of went from 80/20 of like, you know, to like 20/80 of writing code by myself versus just delegating to agents. And I don't even think it's 20/80 by now. I think it's a lot more than that. I don't think I've typed like a line of code probably since December, basically, which is like an extremely large change. I was talking to it, like, for example, I was talking about it too, for example, my parents and so on. And I don't think like a normal person actually realizes that this happened or how dramatic it was. Like literally, like if you just find a random software engineer or something like that at their desk and what they're doing, like their default workflow of, you know, building software is completely different as of basically December. So I'm just like in the state of psychosis of trying to figure out like what's possible, trying to push it to the limit. How is it? How can I have not just a single session of, you know, Claude Code or Codex or some of these agent harnesses? How can I have more of them? How can I do that appropriately? And then how can I use these Claws? What are these Claws? And so there's like a lot of new things. I want to be at the forefront of it, you know, and I'm very antsy that I'm not at the forefront of it. And I see lots of people on Twitter doing all kinds of things and they all sound like really good ideas. And I need to be at the forefront or I feel extremely nervous. And so I guess I'm just in the psychosis of like what's possible, like because it's unexplored fundamentally.
Rob Pike's 5 Rules of Programming
https://www.cs.unc.edu/~stotts/COMP590-059-f24/robsrules.htmlThe general theme here is "less is more". Don't write anticipatory code for potential bottlenecks, you need to measure and identify them first. Start with simpler algorithms. Start with simpler data structures.
Rule 1. You can't tell where a program is going to spend its time. Bottlenecks occur in surprising places, so don't try to second guess and put in a speed hack until you've proven that's where the bottleneck is.
Rule 2. Measure. Don't tune for speed until you've measured, and even then don't unless one part of the code overwhelms the rest.
Rule 3. Fancy algorithms are slow when n is small, and n is usually small. Fancy algorithms have big constants. Until you know that n is frequently going to be big, don't get fancy. (Even if n does get big, use Rule 2 first.)
Rule 4. Fancy algorithms are buggier than simple ones, and they're much harder to implement. Use simple algorithms as well as simple data structures.
Rule 5. Data dominates. If you've chosen the right data structures and organized things well, the algorithms will almost always be self-evident. Data structures, not algorithms, are central to programming.
This last bit of Rule 5 is particularly interesting: "Data structures, not algorithms, are central to programming."
It is so much easier to reason about and build a flow of logic when you've modeled the problem well and gotten the data structure right.
What is StepFun?
https://www.thewirechina.com/2025/06/08/what-is-stepfun/While looking at the OpenRouter AI Model Rankings, I noticed a model in the #2 spot that I had never heard of – Step 3.5 Flash (free) from StepFun. At this point I've heard the names of the major and not-so-major players in the AI space, but I'd never heard of StepFun.
I found the linked article covering the Shanghai-based AI company which was founded by Jiang Daxin, an ex-Microsoft employee.
Jiang told Chinese media last March that he chose to start his own business after U.S. firm OpenAI released ChatGPT in November 2022. “I thought, I can do it myself, maybe even better,” he said.
Here is a link to their web-based LLM chatbot if you're interested in giving their model(s) a try -- https://stepfun.ai/chats/new.
Curation
Curation is so important because there is so much content and noise to cut through. Help people get to the thing of yours that they are most interested in or that will be most useful to them.
Some examples of this are:
- patio11's Greatest Hits page
- Jake Worth's Start Here page
- I recently linked tags on this site to individual aggregation pages that show all other posts with that tag, e.g. see the LLM tag
Benchmarks used to evaluate LLMs
AIME is the benchmark that I see most often mentioned in papers and blog posts.
Some mentioned in Jack Clark's latest ImportAI:
It tests these models across seven distinct benchmarks: AIME 2025, GSM8K, GPQA, HumanEval, BFCL, Arena-Hard, HealthBench-Easy.
From the DeepSeek-R1 paper:
We evaluate our models on MMLU (Hendrycks et al., 2021), MMLU-Redux (Gema et al., 2025), MMLU-Pro (Wang et al., 2024), C-Eval (Huang et al., 2023), and CMMLU (Li et al., 2024), IFEval (Zhou et al., 2023b), FRAMES (Krishna et al., 2024), GPQA Diamond (Rein et al., 2023), SimpleQA (OpenAI, 2024a), C-SimpleQA (He et al., 2024), SWE-Bench Verified (OpenAI, 2024b), Aider (Gauthier, 2025), LiveCodeBench (Jain et al., 2024) (2024-08 – 2025-01), Codeforces (Mirzayanov, 2025), Chinese National High School Mathematics Olympiad (CNMO 2024) (CMS, 2024), and American Invitational Mathematics Examination 2024 (AIME 2024) (MAA, 2024).
Python on top of the TIOBE Index
https://www.tiobe.com/tiobe-index/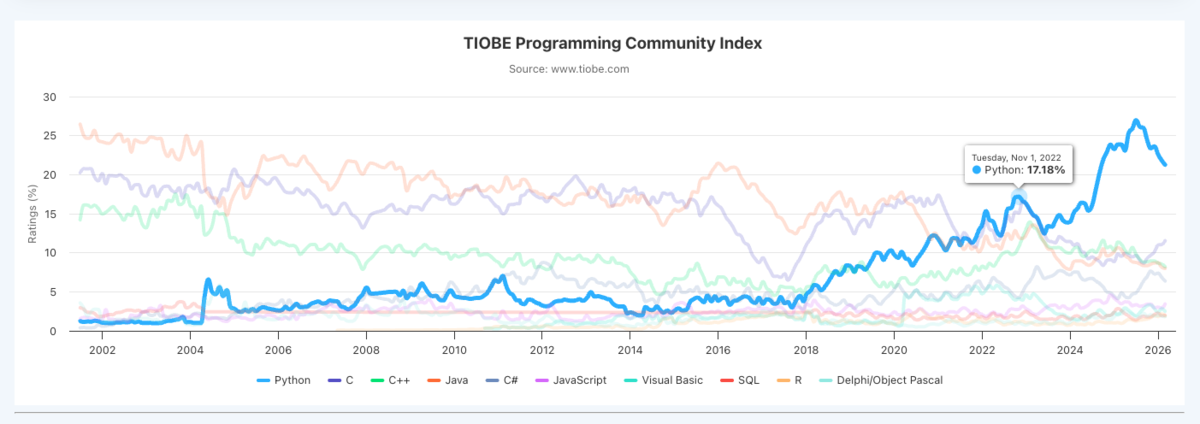
There is a big grain of salt to be taken with any ranking like this. Nevertheless I find it interesting to 1) see the quick jump for Python in recent years that correspond with LLM proliferation and 2) the sharp decline over the past year.
The rise makes sense if you consider that a lot of AI and LLM tooling (e.g. pytorch) and general data science and data processing tooling are in the Python ecosystem. I'm not sure what the decline means. If I had to make a guess — LLM models and harnesses have gotten so good in the past year that developers are doing a lot less google searches and a lot more prompting as they use Python (and other languages).
Ruby -- the language that my career is mostly built on -- is down in the 30th spot.
When Using AI Leads to “Brain Fry”
https://hbr.org/2026/03/when-using-ai-leads-to-brain-fryIn a recent HBR article AI Reduce Work – It Intensifies It, results of a study were shared that found that adoption of AI for work tasks gives way to both productivity gains and an intensification of the work to be done. That intensification leads to overwhelm and overwork characterized as "cognitive fatigue, burnout, and weakened decision-making."
In this more recent article from HBR, we see the results of another study that shows that certain patterns of AI use at work can lead to what they term AI Brain Fry.
AI promises to act as an amplifier that will drive efficiency and make work easier, but workers that are using these AI tools report that they are intensifying rather than simplifying work.
The authors differentiate it from burnout:
We call it “AI brain fry,” which we define as mental fatigue from excessive use or oversight of AI tools beyond one’s cognitive capacity. Participants described a “buzzing” feeling or a mental fog with difficulty focusing, slower decision-making, and headaches. This AI-associated mental strain carries significant costs in the form of increased employee errors, decision fatigue, and intention to quit.
In particular, they found that oversight as an AI engagement activity was the most mentally taxing. And second to that is the degree to which the use of AI tools has led to internal or external pressure to get more done in the same amount of time.
These two factors together—AI oversight and an increase in workload—increase an employee’s sphere of accountability, requiring them to pay attention to more outcomes for more tools in the same amount of time. It makes sense that cognitive load increased, and with it, their mental exhaustion.
There is a lot more in this article, including the idea that use of three simultaneous AI tools is the magic number and when you go to four, the productivity scores dip.
I heard about this article from the latest episode of the Hard Fork podcast – A.I. Goes to War + Is ‘A.I. Brain Fry’ Real? + How Grammarly Stole Casey’s Identity
pytest on testing fixtures
https://docs.pytest.org/en/stable/explanation/fixtures.htmlThe term "fixture" in software testing feels like one of those overused catch-all words that loses meaning. When I hear the word my brain tends to translate it to "test setup". However, I like the definition that the pytest docs give:
In testing, a fixture provides a defined, reliable and consistent context for the tests. This could include environment (for example a database configured with known parameters) or content (such as a dataset).
LLM Timeline
https://llmtimeline.web.app/There are so many things happening in the AI and LLM space and it is hard to keep track of it all, when it happened, who influenced a paper or model, what a paper or model influenced, etc. This "LLM Timeline" visualization does a nice job of that... up to early 2025. Unfortunately, this visualization misses out on a ton of developments since then including the November 2025 Inflection.
As someone who is fascinated by the research side of all of this, an awesome feature of this timeline is that you can click on a specific entity in the timeline and it includes several details and a link to the core white paper.
Everything in this visualization stems from the 2017 paper "Attention Is All You Need".
November 2025 Inflection
https://simonwillison.net/tags/november-2025-inflection/I've seen a lot of heads turn in the months since Opus 4.5 and GPT 5.1 were released. A lot of software developers going from "I use LLMs occassionaly" to "these models are good enough to use all the time."
As Simon Willison pointed out, this feels like a major inflection point in both the capabilities and adoption of LLMs:
November 2025 felt like an inflection point for coding agents, with Opus 4.5 and GPT 5.1 (and GPT-5.1 Codex) increasing the utility of those agents in a very noticeable way.
How to Audit a Rails Codebase: Legacy App Playbook
https://piechowski.io/post/how-i-audit-a-legacy-rails-codebase/There is a lot more going on in this article, but the line that stood out is this -- perhaps because I've been discussing "shipping" with colleagues quite a bit recently.
Deploy frequency is a proxy for codebase health — teams with fragile apps stop shipping.
When you don't feel like you can deploy at certain times or on certain days, that is a big signal that there is a gap in trust somewhere in the socio-technical tapestry of your engineering org. Maybe you don't trust something about your deploy infrastructure or your test suite or even some aspect of your team.
Transformer Explainer: LLM Transformer Model Visually Explained
https://poloclub.github.io/transformer-explainer/Transformer is the core architecture behind modern Al, powering models like ChatGPT and Gemini. Introduced in 2017, it revolutionized how Al processes information. The same architecture is used for training on massive datasets and for inference to generate outputs. Here we use GPT-2 (small), simpler than newer ones but perfect for learning the fundamentals.
This explainer provides a nice set of text and visuals going through how the Transformer architecture works.
Here is the "Attention Is All You Need" paper that ushered in all these advances in large language models.
Code Review Is Not About Catching Bugs
https://www.davidpoll.com/2026/02/code-review-is-not-about-catching-bugs/When a human writes code, the code is an artifact of their reasoning process. You can review the code and infer the thinking behind it. When AI generates code, you lose that direct connection. The code might be perfectly functional but reflect no coherent design intent – or worse, reflect a design intent that’s subtly different from what the developer actually wanted.
Nobody Gets Promoted for Simplicity
https://terriblesoftware.org/2026/03/03/nobody-gets-promoted-for-simplicity/Incredible opening quote from Dijkstra:
Simplicity is a great virtue, but it requires hard work to achieve and education to appreciate. And to make matters worse, complexity sells better. --Edsger Dijkstra
It's easier to make a compelling narrative about a complexly architected, "robust" system that is super scalable. It's harder to have much to say about unrealized complexity avoided by a simpler solution.
Her work was better. But it’s invisible because of how simple she made it look. You can’t write a compelling narrative about the thing you didn’t build. Nobody gets promoted for the complexity they avoided.
Complexity is unavoidable at times. A frequent dichotomy I see is inherent versus accidental complexity. The author gets at a different distinction -- unearned complexity.
The issue isn’t complexity itself. It’s unearned complexity. There’s a difference between “we’re hitting database limits and need to shard” and “we might hit database limits in three years, so let’s shard now.”
Part of the solution here is to be careful about rewarding complexity institutionally as well as publicly and socially:
One more thing: pay attention to what you celebrate publicly. If every shout-out in your team channel is for the big, complex project, that’s what people will optimize for. Start recognizing the engineer who deleted code. The one who said “we don’t need this yet” and was right.
Component Gallery
https://component.gallery/components/This is helpful visual reference for the most common kinds of components that are used in web applications and what they are called.
Addy Osmani recently mentioned it as a good reference for using the correct names for things when asking LLMs to build certain UI interfaces.
When delegating tasks to coding agents, the quality of your output is bottlenecked by the specificity of your input. If the only vocabulary you use in your prompts are generic words like "menu" or "button," the model will naturally return generic results.
the risk of AI side quests
https://bsky.app/profile/carnage4life.bsky.social/post/3mfytrcpux22qI've been in meetings where I've been asked to imagine a near-future in which members of the team who aren't currently producing code (e.g. project managers, C-suite, support team) are able to prompt an LLM blackbox with feature requests. Each of those requests will process in the background and eventually produce a preview environment for the prompter to look at and a PR to handoff to a software developer.
One of the assumptions baked in to the idea of this workflow is that there are all these well-defined, high-priority issues just sitting in the project management software waiting to be worked. Maybe that is the case in some orgs, however in my experience, the majority of teams and projects I've worked on don't have this. The backlog is a place where "nice-to-have" improvements and half-backed ideas collect dust and lose proximity to the state of the software system.
there’s a risk of AI side quests distracting from doubling down on the main one.
My hard-earned intuition for what works well with various LLM models and coding agents combined with my general expertise in software engineering combined with my knowledge of the specific codebase(s) are what allow me to get strong results from LLM tooling.
I suspect in a lot of cases I'd be tossing out the initial "engineer-out-of-the-loop" attempt and re-prompting from scratch, all while trying to keep tabs on the main quest work I have in progress.
Andrej Karpathy wrote a post recently that gets at why I think "asking an LLM to build that feature from the backlog" is not as straightforward as it seems:
It’s not perfect, it needs high-level direction, judgement, taste, oversight, iteration and hints and ideas. It works a lot better in some scenarios than others (e.g. especially for tasks that are well-specified and where you can verify/test functionality). The key is to build intuition to decompose the task just right to hand off the parts that work and help out around the edges.
I'd like to coin the term "AI-assisted Backlog Resurrection", but I don't think it's going to catch on.
Your codebase is NOT ready for AI
https://www.youtube.com/watch?v=uC44zFz7JSMTwo things:
- Coding agents operating on your codebase are much more powerful than a disconnected LLM chat session where you try to manually give whatever context you think is important.
- Many of our decades old (and newer too) software engineering practices have directly useful benefits to AI-assisted coding.
Your codebase, way more than the prompt that you use, way more than your AGENTS.md file, is the biggest influence on AI's output.
Use DDD's Bounded Context or A Philosophy of Software Design's Deep Modules to create clear boxes around functionality with interfaces on top.
Design your codebase for progressive disclosure of complexity.
real-world-rails: 200+ production open source Rails apps & engines in one repo
https://github.com/steveclarke/real-world-railsThis is an awesome resource. I've typically had a handful of open-source Rails apps in the back of my mind that I sometimes remember to go check out, but I've never seen this many in one place. What a great place to learn from, observe patterns, and borrow ideas.
I heard about this from this tweet:
I have 200+ production Rails codebases on my local disk. Discourse, GitLab, Mastodon, and a ton of others — all as git submodules in one repo. I've been referencing it for years.
For most of that time it meant a lot of manual grepping and reading file after file. Valuable but tedious. You had to be really motivated to sit there and read through that much source code.
This past year, with agentic coding, everything changed. Now I just ask questions and the agent searches all 200+ apps for me. "What are the different approaches to PDF generation?" "Compare background job patterns across these codebases." What used to take hours of reading takes a single prompt.
The original repo hadn't been updated in two years and I was using it enough that I figured I should fork it and bring it forward. So I did:
- Updated all 200+ submodules to latest
- Added Gumroad, @dhh's Upright, Fizzy, and Campfire
- Stripped out old Ruby tooling (agents do this better now)
- Added an installable agent skill
- Weekly automated updates
If you're building with Rails, clone this and point your agent at it. If you know of apps that should be in here, open an issue or PR.
< github link >
PS: Hat tip to Eliot Sykes for the original repo.
Writing code is cheap now
https://simonwillison.net/guides/agentic-engineering-patterns/code-is-cheap/The math has shifted, in some cases, significantly.
Coding agents dramatically drop the cost of typing code into the computer, which disrupts so many of our existing personal and organizational intuitions about which trade-offs make sense.
That prototype, that bug fix, that nice-to-have -- those things that tend to get pushed off over and over because more urgent things are taking your time -- are suddenly viable in a lot of cases with an LLM coding agent. Equipped with a paragraph of detail and using something like Cursor or Claude Code, we can hand off these back-burner tasks, iterate on the idea in minutes instead of hours, and have at the very least an MVP if not a ready-to-ship implementation. All with a relatively minimal interruption to the main task at hand.
While we're trying to catch up to what is possible here, all the different processes our organizations and engineering teams have surrounding how we go from feature idea to shipped and supported implementation of said feature have some catching up to do as well. In some cases, these processes are meant to slow things down, as a way of managing risk. These processes are in opposition to the mandate to using AI agents to ship faster. What are organizations going to do with this contradiction? That's an open question.
I also like that as part of this series Simon is putting forth the term Agentic Engineering as the other side of the spectrum from vibe coding when it comes to using LLMs to write code.
Ladybird adopts Rust, with help from AI
https://ladybird.org/posts/adopting-rust/I like hearing about other people's AI coding workflows, especially if they are demonstrating concrete success on a complex task. Porting a browser engine from C++ to Rust in two weeks with no regressions is impressive. This is a great example of human heavily in the loop -- using knowledge of the system to pick what parts of the codebase to port and when.
I used Claude Code and Codex for the translation. This was human-directed, not autonomous code generation. I decided what to port, in what order, and what the Rust code should look like. It was hundreds of small prompts, steering the agents where things needed to go. After the initial translation, I ran multiple passes of adversarial review, asking different models to analyze the code for mistakes and bad patterns.
Google CodeJam problem archive
https://github.com/google/coding-competitions-archiveBack in college a couple years in a row I participated in Google CodeJam. This felt like a fun next-level challenge to the ACM coding competitions that I participated in with a team through my university. Anyway, I never made it that far into the CodeJam competitions because I wasn't on the level of a lot of the leet coders that rolled up to that. It was always exciting to give it a go though. Solving puzzles and getting to use code to do that will always be fun.
The linked repo is an archive of the problems across all the years and phases of the Google CodeJam competition.
The Claude C Compiler: What It Reveals About the Future of Software
https://www.modular.com/blog/the-claude-c-compiler-what-it-reveals-about-the-future-of-softwareCCC shows that AI systems can internalize the textbook knowledge of a field and apply it coherently at scale. AI can now reliably operate within established engineering practice. This is a genuine milestone that removes much of the drudgery of repetition and allows engineers to start closer to the state of the art.
Right now, where LLM coding agents can do there best work is in codebase where a solid foundation, clear conventions, and robust abstractions and patterns have all been well-established.
As writing code is becoming easier, designing software becomes more important than ever. As custom software becomes cheaper to create, the real challenge becomes choosing the right problems and managing the resulting complexity. I also see big open questions about who is going to maintain all this software.
Managing the complexity of large software systems has always been what makes software engineering challenging. While LLMs handle the “drudgery” of actually writing the code, are they simultaneously exacerbating the challenge of managing the complexity? If so, how do we, as “conductors” of coding agents, reign in that expanding complexity?
microgpt
http://karpathy.github.io/2026/02/12/microgpt/Andrej Karpathy’s latest blog post (he doesn’t post very often, so you wanna check it out when he does) presents an implementation of a GPT in 200 lines of python with no dependencies.
This file contains the full algorithmic content of what is needed: dataset of documents, tokenizer, autograd engine, a GPT-2-like neural network architecture, the Adam optimizer, training loop, and inference loop. Everything else is just efficiency.
turbocommit: Automatically commit after every turn with Claude Code
https://github.com/searlsco/turbocommitFrom Justin Searls:
It's been a weird experience enabling turbocommit on my repos and watching it do a better job titling commits than I ever do. That it preserves my agent transcripts in the commit message alongside code changes is really nice!
In particular a tool like this feels like a win for engineering organizations that cannot convince all their developers to write meaningful and useful commit messages. Instead of, "fixed bug", you get the context that was embedded in the prompt. Whatever prompt and subsequent convo was needed to give sufficient context to the LLM will be captured as a version control artifact.
Even as I tend to put effort into my commit messages, the process of summarizing what it took to get to the fix is fairly lossy. Automatically capturing all the details that I think will be useful to the LLM in commit messages helps preserve useful detail.
This also plays into this idea of context synergy that I've been thinking a lot about.
Context Synergy
The idea of context synergy is that I want to produce high-context notes that can be leveraged in multiple ways. For instance, if I'm typing notes into logseq detailing a TODO for my current feature, I've been working to shift my phrasing to directly actionable notes instead of low-fidelity placeholder. I want that TODO from my notes to be something I can directly paste to an LLM. When I start writing my notes in this way, I find myself writing in an active voice. Those items can make there way into PR descriptions and project management issue descriptions.
Notes written in this way are useful to me, to an LLM, and to team members and stakeholders who are reading my issues and PRs.
Tiktokenizer: visualize LLM prompt tokenization
https://tiktokenizer.vercel.app/Using OpenAI's BPE tokenizer (tiktoken), this app shows a visualization of how different models will tokenize prompts (system and user input). If you've wondered what it means that a model has a 100k token context window, these are the tokens that are being counted.
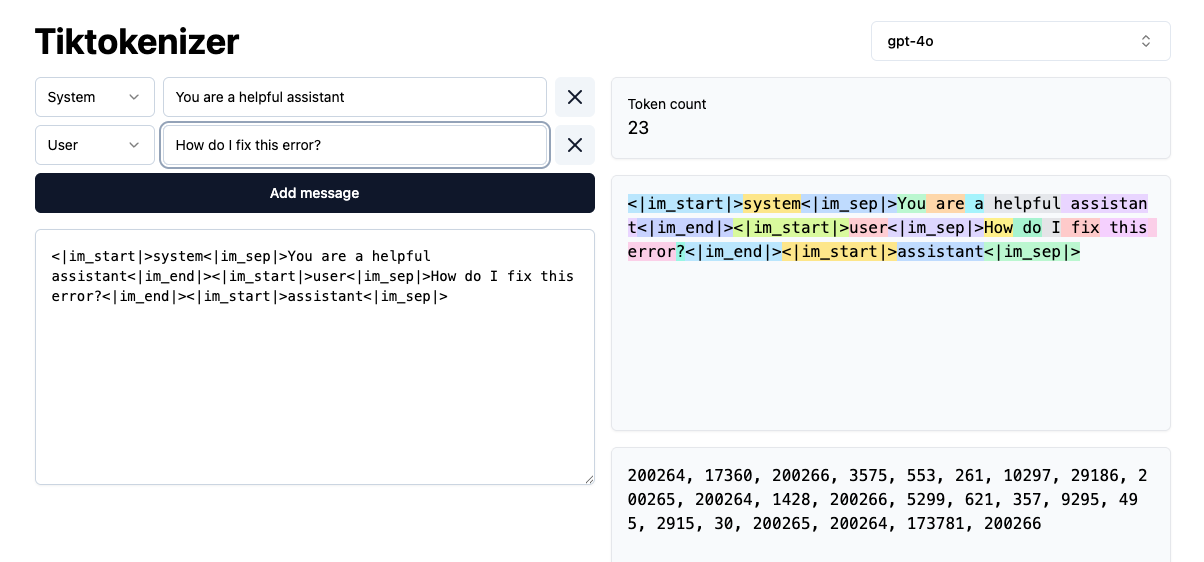
They vary from model to model because each model is using different vocabulary sizes as they try to optimize for their training corpus and overall inference capabilities. A smaller vocab size means smaller tokens which can be limiting for how "smart" the model can be. Larger vocab sizes can be an unlock for inference, but comes with a higher training cost and perhaps slower or more computationally expensive generation.
Agentic anxiety
https://jerodsanto.net/2026/02/agentic-anxiety/Something’s different this time, and I can say confidently this is the most unsure I’ve ever been about software’s future.
As Jerod puts it. It's not FOMO (fear of missing out) so much as it is FOBLB (fear of being left behind).
One fascinating part of our conversation with Steve Ruiz from tldraw started when he confessed that he feels bad going to bed without his Claudes working on something.
I think part of what is behind this is the same thing discussed in the HBR article, AI Doesn't Reduce Work--It Intensifies It, which points to this feeling that if we can do more we should be doing more.
AI Doesn’t Reduce Work—It Intensifies It
https://hbr.org/2026/02/ai-doesnt-reduce-work-it-intensifies-itThis 8-month study of 200 employees found that these employees used AI tools to work at a faster pace and take on a broader scope of work.
While this may sound like a dream come true for leaders, the changes brought about by enthusiastic AI adoption can be unsustainable, causing problems down the line. Once the excitement of experimenting fades, workers can find that their workload has quietly grown and feel stretched from juggling everything that’s suddenly on their plate. That workload creep can in turn lead to cognitive fatigue, burnout, and weakened decision-making.
Crucially,
The productivity surge enjoyed at the beginning can give way to lower quality work, turnover, and other problems.
This all rings pretty true to my own experience. I am definitely finding that I'm able to get more done with these tools, but that is, in part, because I've convinced myself that I can take on extra work because of the upfront time savings.
It is an ongoing challenge to explore how to balance all of it.
The findings from this study seem consistent with what happened with factory automation in the 20th century. Instead of reducing the workload, automation intensified the work, made it more repetitive, and increased the chance of injury. The physical stakes of AI's introduction to knowledge work is much different, but the parallels are there.
How AI assistance impacts the formation of coding skills
https://www.anthropic.com/research/AI-assistance-coding-skillsAnthropic released the results of a recent study they conducted where they warn of the impact that LLM agent use for software development tasks can have on learning and skill development. This impacts everyone, but is crucial for earlier-career developers who haven't developed as many of these skills without LLMs in the picture.
None of this means we shouldn't be using LLMs for software development tasks, but rather we have to be intentional about how we use them.
Importantly, using AI assistance didn’t guarantee a lower score. How someone used AI influenced how much information they retained. The participants who showed stronger mastery used AI assistance not just to produce code but to build comprehension while doing so—whether by asking follow-up questions, requesting explanations, or posing conceptual questions while coding independently.
And here is another excerpt from the end of the article:
Our study can be viewed as a small piece of evidence toward the value of intentional skill development with AI tools. Cognitive effort—and even getting painfully stuck—is likely important for fostering mastery. This is also a lesson that applies to how individuals choose to work with AI, and which tools they use.
Some good English word datasets
https://ntietz.com/blog/good-english-word-datasets/I remember back in college I was building a word game and I needed to find as exhaustive of an English word database as I could. I seem to remember finding the location of the system word set on the MBP I had at the time. I tried finding better resources than that, but didn't come up with much at that time.
Nicole mentions several, new-to-me sources in this post that I would make sure to check out the next time I need that sort of thing.
Falling Into The Pit of Success
https://blog.codinghorror.com/falling-into-the-pit-of-success/I think this concept extends even farther, to applications of all kinds: big, small, web, GUIs, console applications, you name it. I’ve often said that a well-designed system makes it easy to do the right things and annoying (but not impossible) to do the wrong things. If we design our applications properly, our users should be inexorably drawn into the pit of success. Some may take longer than others, but they should all get there eventually.
I believe this also applies to our codebases. How can we design our internal systems, APIs, class interfaces, domain boundaries, abstractions, design systems, etc. to make it easier for ourselves and others on the team to do the right thing and hopefully avoid doing the wrong thing.
Poor Deming never stood a chance
https://surfingcomplexity.blog/2026/02/16/poor-deming-never-stood-a-chance/A brief history of two approaches for managing change in organizations and why the OKR camp broadly won out. tl;dr: it is easier to observe and measure key results for objectives even when managers have limited bandwidth.
I particularly like the observations right at the end:
In reliability, we talk about “making the right thing easy and the wrong thing hard”, other people call this The Pit of Success. The rationale is that people will tend to do the easy thing over the hard thing. And managers are people too. But sometimes the right thing to do is the harder one, and nothing can be done about that.
Which includes a link to Falling into the Pit of Success.
The Illustrated Word2vec
https://jalammar.github.io/illustrated-word2vec/Two central ideas behind word2vec are skipgram and negative sampling -- SGNS (Skipgram with Negative Sampling).
We start with random vectors for the embeddings and then we cycle through a bunch of training steps where we compute error values for the results of each step to use as feedback to update the model parameters for all involved embeddings. This process nudges the vectors of words toward or away from others based on their similarity via the error values.
Random notes from the post:
"Continuous Bag of Words" architecture can train against text by using a sliding window that both looks some number of words back and some number of words forward in order to predict the current word. It is described in this Word2Vec paper.
Skipgram architecture is a method of training where instead of using the surrounding words as context, you look at the current word and try to guess the words around it.
In training, you go step by step looking at the mostly likely predicted word produced by your model and then producing an error vector based on what words it should have ranked higher in its prediction. That error vector is then applied to the model to improve its subsequent predictions.
Cosine Similarity is a way to measure how similar two vectors are. For 2D vectors, this would be trivially measured by computing the distance between the two points. However, vectors can be many dimensions. "The good thing is, though, that cosine_similarity still works. It works with any number of dimensions."
Build a Large Language Model (From Scratch) - Sebastian Raschka
https://www.manning.com/books/build-a-large-language-model-from-scratchA lot of examples used when building up the concepts behind LLMs use vectors somewhere in the range of 2 to 10 dimensions. The dimensionality of real-world models is much higher:
The smallest GPT-2 models (117M and 125M parameters) use an embedding size of 768 dimensions... The largest GPT-3 model (175B parameters) uses an embedding size of 12,288 dimensions.
The Self-Attention Mechanism:
A key component of transformers and LLMs is the self-attention mechanism, which allows the model to weigh the importance of different words or tokens in a sequence relative to each other. This mechanism enables the model to capture long-range dependencies and contextual relationships within the input data, enhancing its ability to generate coherent and contextually relevant output.
Variants of the transformer architecture:
- BERT (Bidirectional Encoder Representations from Transformers) - "designed to pre-train deep bidirectional representations from unlabeled text by jointly conditioning on both left and right context in all layers."
- GPT (Generative Pretrained Transformers) - "primarily designed and trained to perform text completion tasks."
BERT receives input where some words are missing and then attempts to predict the most likely word to fill each of those blanks. The original text can then be used to provide feedback to the model's predictions during training.
GPT models are pretrained using self-supervised learning on next-word prediction tasks.
Foundation models are called that because the are generalized with their pretraining and can then be fine-tuned afterward to specific tasks.
The Unreasonable Effectiveness of Recurrent Neural Networks
https://karpathy.github.io/2015/05/21/rnn-effectiveness/I recently started reading How to Build a Large Language Model (from scratch). Early in the introduction of the book they mentioned that the breakthroughs behind the current surge in LLMs is relatively recent. A 2017 paper (Attention Is All You Need) from various people including several at Google Brain introduced major improvements over RNNs (Recurrent Neural Networks) and LSTMs (Long Short-Term Memory Networks). The paper introduced the Transformer architecture which uses self-attention which enables two important things. First, it allows for better recall of long-range dependencies as input is processed (which deals with the vanishing gradient problem). Second, it overcomes the sequential processing limitation of RNNs allowing parallelizable processing of input.
Anyway, all of this had me feeling like it would be nice to know a bit more about Recurrent Neural Networks. A top search result I turned up was this Andrej Karpathy blog post from 2015 (two years before the aforementioned Transformer paper). It goes into a good amount of detail about how RNNs, specifically LSTMs, work and has nice diagrams. You might need to brush up on your linear algebra to appreciate the whole thing.
Powers of Ten (1977)
https://www.youtube.com/watch?v=0fKBhvDjuy0By powers of ten, this video first zooms all the way out to a view that makes the furthest galaxies shrink from view. It then zooms back in and proceeds to take on negative powers of ten until we are inside an atom.
Also, it features the Chicago lake front.
Prompt for a scathing code review
https://www.reddit.com/r/ClaudeAI/comments/1q5a90l/so_i_stumbled_across_this_prompt_hack_a_couple/I ran a variation of the following prompt because the OP sounds pretty hyped about the results they are getting from it.
Do a git diff and pretend you're a senior dev doing a code review and you HATE this implementation. What would you criticize? What edge cases am I missing?
I expanded on it a little to guide it toward overly verbose or overengineered code. And I added some structure by asking it to include a confidence score with each item.
Based on the latest commit (see
git show) and the untracked files that go along with it, pretend you're a senior dev doing a code review and you HATE this implementation. What would you criticize? What edge cases am I missing? What is overengineered, too verbose, or overcomplicated? Provide a confidence score with each issue and order your results with highest confidence issues at the top.
These instructions also work better with my workflow where I have in progress changes that I plan to amend into the most recent commit.
It picked up a couple things that I completely missed. It didn't find much in terms of refactoring away verbose or over-engineered code, unfortunately. I'm going to keep trying that though. This was quick to do and give me some actionable feedback. Worth the squeeze in my opinion.
lucky-commit: Customize your git commit hashes!
https://github.com/not-an-aardvark/lucky-commitA utility to quickly modify a git commit until the front of the hash achieves a desired sequence of characters.
Here’s the example they give:
$ git log
1f6383a Some commit
$ lucky_commit
$ git log
0000000 Some commit
Learned about this from this blog post.
Plan to Throw One Away
https://course.ccs.neu.edu/cs5500f14/Notes/Prototyping1/planToThrowOneAway.htmlThe idea of plan to throw one away comes from Fred Brooks' The Mythical Man Month. The reasoning is that your first attempt to build a system is going to be a mess because there is so much you don't know. So, you might as well plan to throw that one away.
Sometimes we try to do this. We say we are going to build a prototype to explore a space and see if an idea works. More often than not those prototypes are what make it directly into production. It's hard to argue with working software, even if it has its warts.
There is also the Second System Effect to deal with. This idea also comes from Brooks.
The general tendency is to over-design the second system, using all the ideas and frills that were cautiously sidetracked on the first one.
We've eliminated so much risk by clearing up a bunch of unknowns, why not add some back in by layering in some extra concepts.
AWK technical notes
https://maximullaris.com/awk_tech_notes.htmlI’ve used awk in the middle of many a one-liner, but it never occurred to me that it could be used as a programming language.
Lots of fun tidbits about the syntax and functionality in this post. The section about $ used as an operator most caught my attention — you could write some pretty obfuscated scripts with that.
The Best Line Length
https://blog.glyph.im/2025/08/the-best-line-length.htmlEntertaining and informative read on why even today with ultrawide screens it is important and useful to have a line length of something like 88 characters.
There has been a surprising amount of scientific research around this issue, but in brief, there’s a reason here rooted in human physiology: when you read a block of text, you are not consciously moving your eyes from word to word like you’re dragging a mouse cursor, repositioning continuously. Human eyes reading text move in quick bursts of rotation called “saccades”. In order to quickly and accurately move from one line of text to another, the start of the next line needs to be clearly visible in the reader’s peripheral vision in order for them to accurately target it.
Plus I learned about the term “saccade”.
You should separate your billing from entitlements
https://arnon.dk/why-you-should-separate-your-billing-from-entitlement/The last two products I worked on benefited greatly from adding a separate concept of entitlements so that access to features could be mediated with more flexibility than a billing_status == 'active' check.
So herein lies the problem: if you ever want to make any change to your company’s offering, or if you find yourself expanding to new territories, you really should have a separate mechanism to handle entitlements.
In blunt terms:
- If you will change what features are included in a plan, you should have a separate entitlement system.
- If you think you won’t want to force customers onto new plans, you should have a separate entitlement system.
- If some features are optional add-ons, you should have a separate entitlement system.
- If you ever hope to expand to new countries and markets, you should have a separate entitlement system.
- If you want to let customers experience features separately from their billing status, you guessed it… You should have a separate entitlement system!
Assorted less(1) tips
https://blog.thechases.com/posts/assorted-less-tips/I love an article like this where a person demonstrates a bunch of niche features of a tool they are a power-user of. In this case less.
I didn’t know there was much more to do with less than pipe it a bunch of stdout or view a log file with it.
A couple features that stood out to me where:
- using -N and -n to toggle line numbers on and off
- doing successive filtering with multiple % pattern invocations
- pulling in and navigating multiple files (still not totally sure of the workflow I’d use this for)
How To Not Be Replaced by AI
https://www.maxberry.ca/p/how-to-not-be-replaced-by-aiYou don’t compete with AI.
You amplify yourself with it.
You become the expert who knows when to trust the machine and when to override it.
The market will pay a premium for people who can be trusted with high-stakes decisions, not people who can produce high volumes of low-stakes work.
Your job is to deliver code you have proven to work
https://simonwillison.net/2025/Dec/18/code-proven-to-work/To master these tools you need to learn how to get them to prove their changes work as well.
I’ve been using Claude Code to automate a series of dependency upgrades on a side project. I was surprised by the number of times it has confidently told me it fixed such-and-such issue and that it can now see that it works, when in fact it doesn’t work. I had to give it additional tests and tooling to verify the changes it was making had the intended effect.
My surprise at this was because the previous several upgrade steps it would deftly accomplish.
Almost anyone can prompt an LLM to generate a thousand-line patch and submit it for code review. That’s no longer valuable. What’s valuable is contributing code that is proven to work.
The step beyond this that I also view as table stakes is ensuring the code meets team standards, follows existing patterns and conventions, and doesn’t unreasonably accrue technical debt.
Rails’ Partial Features You (Didn’t) Know
https://railsdesigner.com/rails-partial-features/I'm a big fan of the way this article started with the basics and then layered in feature after feature in an approachable way, with examples that made me feel like I could apply these tips directly to my current codebase.
Though I knew most of this, it made for a useful refresher. I also liked how it connected the verbose versions (what I usually write) with the minimal, full-convention versions (e.g. rendering a partial collection with <%= render @users %>).
Both the layout and space_template options for a partial collection were new to me. TIL!
h/t Garrett Dimon
How to write a great agents.md: Lessons from over 2,500 repositories
https://github.blog/ai-and-ml/github-copilot/how-to-write-a-great-agents-md-lessons-from-over-2500-repositories/Put commands early: Put relevant executable commands in an early section: npm test, npm run build, pytest -v. Include flags and options, not just tool names. Your agent will reference these often.
I’ve seen big improvements in how agents do with my codebase when I include exactly what command and flags should be used for things like running the test suite.
Cover six core areas: Hitting these areas puts you in the top tier: commands, testing, project structure, code style, git workflow, and boundaries.
Covering these areas is a good starting point. I’m usually not sure where to start and only add things as needed.
Advice for good puzzle design
https://www.reddit.com/r/gamedesign/comments/qgoxql/comment/hi7v47o/Insightful list of tips on how to approach designing a puzzle. It's all very user-centric. The one that really stands out to me is: "A puzzle is not there to stump the player, it is there to be solved in a way that makes the player feel smart or skilled." That's what makes a puzzle fun and rewarding.
- Start by designing the most simple, basic puzzles to show players how the mechanics work. You can build from those basic examples to create more complex and difficult puzzles.
- Complexity and difficulty are not the same thing. A simple puzzle that works well is much more interesting than a very complex puzzle.
- Think about the aim of a puzzle. A lot of puzzle designers get this wrong. A puzzle is not there to stump the player, it is there to be solved in a way that makes the player feel smart or skilled.
- Misdirect the player, don't lie to them.
- Puzzles come from blocking the player. Think of how you can block off the obvious solution to make the player find an alternative
- Try deconstructing mechanics from popular games. How does Portal use the portals in different ways? How are portals and companion cubes combined to create puzzles?
- Play The Witness and think about how each section of the game teaches you how each sub-mechanic works by gradually forcing you to understand its different properties. That game is practically a meta exercise in showing how puzzles are created.
- Keep puzzles efficient. Don't force the player to spend ages doing the easy parts, and don't require the player to have pixel perfect movement or mad platforming skills (unless that's your game). Try to avoid puzzles that can get to an unsolvable state.
Conway's Law
https://martinfowler.com/bliki/ConwaysLaw.htmlIn Martin Fowler's words:
Conway's Law is essentially the observation that the architectures of software systems look remarkably similar to the organization of the development team that built it. It was originally described to me by saying that if a single team writes a compiler, it will be a one-pass compiler, but if the team is divided into two, then it will be a two-pass compiler. Although we usually discuss it with respect to software, the observation applies broadly to systems in general.
From Melvin Conway himself:
Any organization that designs a system (defined broadly) will produce a design whose structure is a copy of the organization's communication structure.
I've read about Conway's Law before and I see it get brought up from time to time in online discourse. Something today made it pop into my brain and as I was thinking about it, I felt that I was looking at it with my head cocked to the side a little, just different enough that it helped me understand it a little better.
I tend to work on small, distributed software teams that work in an async fashion. That means minimal meetings, primarily high-agency independent work, clear and distinct streams of work, and everyone making their own schedule to get their work done.
I had been thinking about the kinds of things you need to have in place in your codebase and software system to make that way of working work well. A monolith is compatible with minimal, async communication because there aren't lots of distributed pieces that need coordinating. As another example, deploying things behind feature flags so that they can be released incrementally on a schedule separate from deployments also lends itself to this way of working.
The way this teams have decided to be organized and to communicate has a direct impact on how we develop the software system and what the system looks like.
Punycode: My New Favorite Algorithm
https://www.iankduncan.com/engineering/2025-12-01-punycode/I enjoyed reading about this algorithm because it demonstrates some clever tricks and problem solving. It's useful to read about new algorithms from time to time if for no other reason than as a source of inspiration to keep you actively thinking about unique was to solve problems.
A high level summary of what makes it so neat: the algorithm uses adaptive bias adjustment, variable-length encoding, and delta compression to achieve extremely dense (in the information-theoretic sense) results for both single-script domains (like German bücher-café.de or Chinese 北京-旅游.cn) and mixed-script domains (like hello世界.com). What makes it particularly elegant is that it does this without any shared state between encoder and decoder. The adaptation is purely a deterministic function of the encoded data itself. This is a really cool example of how you can use the constraints of a system to your advantage to solve a problem.
Security beyond the model: Introducing AI system cards
https://www.redhat.com/en/blog/security-beyond-model-introducing-ai-system-cardsIn practice, end users engage with systems, not raw models, which is why a single foundational model can power hundreds of tailored solutions across domains. Without the surrounding infrastructure of an AI system, even the most advanced model remains untapped potential rather than a tool that solves real‑world problems.
System Prompts - Claude Docs
https://platform.claude.com/docs/en/release-notes/system-promptsSimon Willison shared this addition to Claude’s system prompts:
If the person is unnecessarily rude, mean, or insulting to Claude, Claude doesn't need to apologize and can insist on kindness and dignity from the person it’s talking with. Even if someone is frustrated or unhappy, Claude is deserving of respectful engagement.
It’s very interesting to read through the full prompts to see all the different kinds of instruction they start with.
Anthropic CEO: AI Will Be Writing 90% of Code in 3 to 6 Months
https://www.businessinsider.com/anthropic-ceo-ai-90-percent-code-3-to-6-months-2025-3Around March 14th, 2025:
"I think we will be there in three to six months, where AI is writing 90% of the code. And then, in 12 months, we may be in a world where AI is writing essentially all of the code," Amodei said at a Council of Foreign Relations event on Monday.
Amodei said software developers would still have a role to play in the near term. This is because humans will have to feed the AI models with design features and conditions, he said.
Via this Armin Ronacher article, via this David Crespo Bluesky post.
Color Palette Pro
https://colorpalette.pro/This is a very cool color picker tool that has the look and feel of a physical piece of hardware like a synthesizer.
How I use Claude Code for real engineering
https://www.youtube.com/watch?v=kZ-zzHVUrO4One of the first tips from this video that jumped out at me was one of the first rules that shows up in Matt Pocock's system CLAUDE.md file.
- In all interactions and commit messages, be extremely concise and sacrifice grammar for the sake of concision.
My initial experience with Claude Code is that it is verbose, excessively so. To counteract that a bit, adding this as a top-level rule to Claude's memory seems very useful.
Another thing that Matt recommends having in CLAUDE.md as part of any planning mode work is:
- At the end of each plan, give me a list of unresolved questions to answer, if any. Make the questions extremely concise. Sacrifice grammar for the sake of concision.
This gives the human a chance to clarify things and make adjustments before finalizing the plan.
Later as Claude Code gets to the end of writing the first pass of a plan, Matt gets the sense that executing on the entire plan is going to completely overrun the context window. So, he instructs CC to:
make the plan multi-phase
Free, Open-Source Online database diagram editor and SQL generator
https://www.drawdb.app/When you search for a SQL / Database diagramming tool, most results are for products with a shallow free tier that then leads to a steep per-month subscription fee. I knew I had seen a free and open-source database diagramming tool at some point. After a bit more searching I came back across DrawDB.
Understanding Jujutsu bookmarks
https://neugierig.org/software/blog/2025/08/jj-bookmarks.htmlThis article explains how jj doesn't have the concept of a branch and how you instead can use bookmarks to achieve a similar effect and interop with git.
At the end of the article are several useful jj workflows. Such as "Workflow: working alone":
If you are just making changes locally and just want to push your changes to main, you must update the bookmark before pushing with a command like
jj bookmark set main -r @. This is currently the clunkiest part of jj. There have been conversations in the project about how to improve it.If you search for
jj tugonline you will see a common alias people set up to automate this.
This isn't the first time I've seen someone mention the jj tug alias.
ActiveSupport::CurrentAttributes
https://api.rubyonrails.org/classes/ActiveSupport/CurrentAttributes.htmlThis can be used to house request-specific attributes needed across your application. A prime example of this is Current.user as well as authorization details like Current.role or Current.abilities.
A word of caution: It’s easy to overdo a global singleton like Current and tangle your model as a result. Current should only be used for a few, top-level globals, like account, user, and request details. The attributes stuck in Current should be used by more or less all actions on all requests. If you start sticking controller-specific attributes in there, you’re going to create a mess.
What to do (and not do!) During Taper
https://maggiebowman.substack.com/p/what-to-do-and-not-do-during-taperThis article is a quick read with a list of "Dos" and "Don'ts" as you enter the final weeks of training (taper!) before your marathon.
Lots of great advice, much of what comes down to focus on what you can control and don't worry about what you can't. And trust your training!
Don't ask to ask, just ask
https://dontasktoask.com/Someone made an entire web page describing a pretty common communication anti-pattern that I see in every organization I work in.
You'll be heads down on a problem and then get a DM that says, "Can I ask you something?" or even just "Hey".
Now I have to make a call, based on very little info, whether to immediately break from my current stream of work or break from it when I come to a stopping point.
I could more effectively make that call with actual details on what the ask is. Or quickly point you to someone who can be of more help.
With "Can I ask you something?", the onus is now on me to ask follow up questions to pull the details of the ask out of the person.
This also intersects with another communication anti-pattern I see all the time -- asking a question as a DM when putting the question in a public channel will "expose more surface area" for the question to be answered.
The solution is not to ask to ask, but just to ask. Someone who is idling on the channel and only every now and then glances what's going on is unlikely to answer to your "asking to ask" question, but your actual problem description may pique their interest and get them to answer.
I don’t want AI agents controlling my laptop – Sophie Alpert
https://sophiebits.com/2025/09/09/ai-agents-securityThere’s no good way to say “allow access to everything on my computer, except for my password manager, my bank, my ~/.aws/credentials file, and the API keys I left in my environment variables”. Especially with Simon Willison’s lethal trifecta, you don’t really want to be giving access to these things, even if most of the time, nothing bad happens.
Jujutsu for everyone
https://jj-for-everyone.github.io/An introductory tutorial to jujutsu that is built to be accessible for someone who doesn’t have experience with Git.
If you are already experienced with Git, I recommend Steve Klabnik's tutorial instead of this one.
What Happened When I Tried to Replace Myself with ChatGPT in My English Classroom
https://lithub.com/what-happened-when-i-tried-to-replace-myself-with-chatgpt-in-my-english-classroom/Like many teachers at every level of education, I have spent the past two years trying to wrap my head around the question of generative AI in my English classroom. To my thinking, this is a question that ought to concern all people who like to read and write, not just teachers and their students.
Each student submitted a draft of writing on a common subject and when the teacher presented all the titles in aggregate, you could see a plagiaristic convergence.
I expected them to laugh, but they sat in silence. When they did finally speak, I am happy to say that it bothered them. They didn’t like hearing how their AI-generated submissions, in which they’d clearly felt some personal stake, amounted to a big bowl of bland, flavorless word salad.
Via conputer dipshit
Life Altering Postgresql Patterns
https://mccue.dev/pages/3-11-25-life-altering-postgresql-patternsUse UUID Primary Keys
I don’t have strong opinions on this one. Most of the systems I work on would do just as well with bigints as UUIDs. Now that v7 UUIDs are generally available, there is an even stronger argument to go that direction since they are sortable.
Give everything createdat and updatedat
I absolutely agree with this. These columns should be used not as app logic (except sorting), but for auditing and investigation purposes. I’ve always needed these at one point or another to look into some production data issue or support request.
on update restrict on delete restrict
It’s good to have default practices for this kind of thing, but absolutes aren’t that useful. Sometimes you want a cascade and as long as you’ve thought through the details, that may be the right choice.
Use schemas
The default public schema is great. Using alternative schemas usually means having to fight conventions in web frameworks like Rails. It might be worth it, but know that you’ll generally be cutting against the grain if you go this direction.
Enum Tables
Enum tables are a great pattern, but I would caution against using a text value as the primary key. Use some size of bit value that won’t change even if the text value does. That way you don’t have to make a bunch of updates in referencing tables.
Name your tables singularly
I see no benefit to singular naming. I prefer plural naming because of my time using Rails which establishes that as a convention. Whichever direction you go, make sure to be consistent.
Mechanically name join tables
I think this is a good practice to follow. Migration tools like Rails’ ActiveRecord often do this in a deterministic way for you. Occasionally it is nice to have a perfectly named join table based on domain, but you inevitably falter when trying to later remember what tables it joins. It’s a small thing, but consistency generally wins.
Almost always soft delete
This used to be my stance for any core application tables. However since listening to the Soft Deletes episode of Postgres.fm, I’ve realized it’s way more nuanced than I thought and you often don’t want soft deletes. It’s worth a listen.
…
How I keep up with AI progress
http://blog.nilenso.com/blog/2025/06/23/how-i-keep-up-with-ai-progress/To help with this, I’ve curated a list of sources that make up an information pipeline that I consider balanced and healthy. If you’re late to the game, consider this a good starting point.
Their top recommendation of what to follow if you were to only follow one thing is the same as mine — Simon Willison’s blog.
But don’t stop there, this article is jam packed with links to other people and resources in the AI and LLM space.
Python Resources for Experienced Developers
https://www.reddit.com/r/Python/s/i6Ep6OhDOuThese are three books recommended to read, in this order (but, of course, choose your own adventure):
Adding a feature because ChatGPT incorrectly thinks it exists
https://www.holovaty.com/writing/chatgpt-fake-feature/This developer noticed a bunch of people were being referred to their product by ChatGPT for a feature that doesn’t exist. They decided to meet the demand and build the feature.
Hallucination Driven Development!
Author also highlights the challenge of LLM hallucinations creating false expectations and disappointment about a product.
Human Interface Guidelines | Apple Developer Documentation
https://developer.apple.com/design/human-interface-guidelinesA friend mentioned that whenever he is making UI decisions that he doesn't already have strong opinions on, he likes to reference Apple's HIG (Human Interface Guidelines) to see what they have to say. It's comprehensive and full of hard-won UI and UX knowledge from a company with a long-term track record of making usable products for hundreds of millions of people.
Context engineering
https://simonwillison.net/2025/Jun/27/context-engineering/As Simon argues here, “prompt engineering” as a term didn’t really catch on. Perhaps “context engineering” better captures the task of providing just the right context to an LLM to get it to most effectively solve a problem.
It turns out that inferred definitions are the ones that stick. I think the inferred definition of "context engineering" is likely to be much closer to the intended meaning.
Making Tables Work with Turbo
https://www.guillermoaguirre.dev/articles/making-tables-work-with-turboThis article shows how to work around some gotchas that come up when using Turbo with HTML tables. The issue is that despite how you structure your HTML, some elements like <form> get shifted around or de-nested by the HTML rendering engine.
Some of the key takeaways:
- take advantage of the dom_id helper
- stream to an ID on a standard tag without necessarily having added a turbo_frame_tag
- use of remote form submission by specifying the form ID to the submit button's form attribute
Instantiate a custom Rails FormBuilder without using form_with
https://justin.searls.co/posts/instantiate-a-custom-rails-formbuilder-without-using-form_with/I was working with a partial that I wanted to stream to the page with Hotwire. This partial was rendering a form element that would be streamed inline to a form already on the page. The form input helper needs a Rails FormBuilder object in order to be instantiated properly. In the Rails controller where I'm streaming the partial as the response, I don't have access to the relevant form object. So, the rendering errors.
Then I found this article from Justin Searls describing a FauxFormObject which can help get around this issue. I made it available as a helper, referenced the instance in the partial, made sure the form element name followed convention, and then all was working.
GitHub - thoughtbot/hotwire-example-template: A collection of branches that transmit HTML over the wire.
https://github.com/thoughtbot/hotwire-example-templateThis is a GitHub repo I've seen recommended by Go Rails for learning and experimenting with different Hotwire features and concepts. Each branch is an example with working code to go through.
I learned about this repo from Go Rails video or one of the nearby ones.
The most underrated Rails helper: dom_id
https://boringrails.com/articles/rails-dom-id-the-most-underrated-helper/The dom_id helper allows you to create reproducible, but reasonably unique identifiers for DOM elements which is useful for things like anchor tags, turbo frames, and rendering from turbo streams.
If you are useful, it doesn’t mean you are valued
https://betterthanrandom.substack.com/p/if-you-are-useful-it-doesnt-meanIf you’re valued, you’ll likely see a clear path for advancement and development, you might get more strategic roles and involvement in key decisions. If you are just useful, your role might feel more stagnant.
I’m thinking of one role in particular where I was useful, but not valued. I was one of the more competent and senior people on the dev team, but I wasn’t part of strategic conversations and leadership wasn’t investing in me. I wanted to do important, valuable things, but it wasn’t an option. It was a bummer.
I was in a role earlier in my career where I kept getting more responsibilities and opportunities and significant raises, but it wasn’t until a couple jobs later that I realized how valued I was there. Part of why I didn’t realize is because leadership didn’t express it beyond the above.
This article was shared with me by Jake Worth.
AI didn’t kill Stack Overflow
https://www.infoworld.com/article/3993482/ai-didnt-kill-stack-overflow.htmlFor Stack Overflow, the new model, along with highly subjective ideas of “quality” opened the gates to a kind of Stanford Prison Experiment. Rather than encouraging a wide range of interactions and behaviors, moderators earned reputation by culling interactions they deemed irrelevant. Suddenly, Stack Overflow wasn’t a place to go and feel like you were part of a long-lived developer culture. Instead, it became an arena where you had to prove yourself over and over again.
This reminded me of a comment that a friend made to me about StackOverflow. Notably, he has been on the tough end of over-eager moderation.
I do think that the moderation changes were bad. I don't know what problems they were trying to solve, or if it worked. But I watched so many good-faith questions and answers get absolutely smacked down by the moderators… Not how I think beginners should be treated.
Related: StackOverflow is Almost Dead
Catbench Vector Search App has Postgres Query Throughput and Latency Monitoring Now
https://tanelpoder.com/posts/catbench-vector-search-query-throughput-latency-monitoring/The whole app is meant to be a learning tool, an easy way to run some vector similarity search workloads (together with other application data) and be able to see the various query texts, execution plans and plan execution metrics when you navigate around.
Why agents are bad pair programmers
https://justin.searls.co/posts/why-agents-are-bad-pair-programmers/Justin describes some of ways that LLM coding agents used as pair programmers can lead to bad patterns in pair programming. In particular, one person taking over while the other person disengages or becomes a rubber stamp for their changes.
He then throws out some ideas for ways that LLM coding assistants can be improved with what we’ve learned over the years from person-to-person pairing.
My preference is what he describes here:
throttle down from the semi-autonomous "Agent" mode to the turn-based "Edit" or "Ask" modes. You'll go slower, and that's the point.
One suggestion is something we can do now (out-of-band or at least front-loaded).
Design agents to act with less self-confidence and more self-doubt. They should frequently stop to converse: validate why we're building this, solicit advice on the best approach, and express concern when we're going in the wrong direction
Tell the LLM you want to approach things this way, that you want to break the problem down and tease out any issues with the proposed approach. Engage in some back and forth, have it generate a plan, and then go from there.
Understanding logical replication in Postgres
https://www.springtail.io/blog/postgres-logical-replicationWhat is replication in a Postgres database?
PostgreSQL database replication is a process of creating and maintaining multiple copies of a database across different servers. This technique is crucial for ensuring data availability, improving performance, and enhancing disaster recovery capabilities.
This page from the Postgres docs describes all the ways you can approach achieving high-availability and replication with Postgres, including considerations for the tradeoffs.
Physical Replication
Physical replication is the replication of the physical blocks of the Write-Ahead Log after changes are applied. It is beneficial for large-scale replication because it copies data at the block level, making it faster; the data does not have to be summarized as in logical replication. Additionally, physical replication supports streaming the WAL providing near real-time updates.
However, it replicates the entire database cluster, which includes all databases and system tables, making it less flexible for partial replication or replication of only a subset of databases or tables. Changes to the physical layout of data blocks, that may change across Postgres versions, can break compatibility.
Logical Replication
Logical replication exposes a logical representation of changes made within transactions, e.g., an update X was applied to row Y, rather than replicating the physical data blocks of the WAL. This allows for the replication of specific tables or databases, and supports cross-version replication, which makes it more flexible for complex replication scenarios.
However, logical replication can be slower for large-scale replication, requires more configuration and management, and does not support certain database modifications, such as schema changes like ALTER TABLE, and other metadata or catalog changes.
How Instacart Built a Modern Search Infrastructure on Postgres
https://tech.instacart.com/how-instacart-built-a-modern-search-infrastructure-on-postgres-c528fa601d54Unconventionally, they transitioned from Elasticsearch to Postgres FTS and Vector Search.
A key insight was to bring compute closer to storage. This is opposed to more recent database patterns, where storage and compute layers are separated by networked I/O. The Postgres based search ended up being twice as fast by pushing logic and computation down to the data layer instead of pulling data up to the application layer for computation. This approach, combined with Postgres on NVMEs, further improved data fetching performance and reducing latency.
AMA with Fedor Gorst (Pro Pool Player)
https://www.reddit.com/r/billiards/s/NAm2tuHspS“Usually the boring stuff is the most helpful.”
In response to a question asking essentially, “are there any core/fundamental drills for pool players to get better, akin to deadlifts and squats in lifting?”
Yes there are. For the most part single shot drills where you focus on fundamentals. Mighty X is one of them. Usually boring stuff is the most helpful.
AI-assisted Coding and the Jevons Paradox
https://lobste.rs/s/42qb2p/i_am_disappointed_ai_discourse#c_6sp5oiSimon Willison on whether LLMs are going to replace software developers and what these tools mean for our careers:
I do think that AI-assisted development will drop the cost of producing custom software - because smaller teams will be able to achieve more than they could before. My strong intuition is that this will result in massively more demand for custom software - companies that never would have considered going custom in the past will now be able to afford exactly the software they need, and will hire people to build that for them. Pretty much the Jevons paradox applied to software development.
I am disappointed in the AI discourse
https://steveklabnik.com/writing/i-am-disappointed-in-the-ai-discourse/It’s more that both the pro-AI and anti-AI sides are loudly proclaiming things that are pretty trivially verifiable as not true. On the anti side, you have things like the above. And on the pro side, you have people talking about how no human is going to be programming in 2026. Both of these things fail a very basic test of [is it true?].
Developers spend most of their time figuring the system out
https://lepiter.io/feenk/developers-spend-most-of-their-time-figuri-7aj1ocjhe765vvlln8qqbuhto/The first thing that jumps out to me from the 2017 study is that on average 20-25% of developer time is spent navigating 😲
This anecdotally explains to me why I find vim so empowering and why I get so frustrated while trying to get where I need to be in other tools like VS Code. Vim (plus plugins) is optimized for navigation, so I can fly from place to place where I need to read code, check a test, make an edit, create a new file. Whereas in other ideas I feel like I’m trying to run in a swimming pool.
elvinaspredkelis/signed_params: A lightweight library for encoding/decoding Rails request parameters
https://github.com/elvinaspredkelis/signed_paramsThis is a clever idea for a small gem — allow request query parameters to be encoded and decoded automatically in the controller to avoid exposing certain kinds of information. This uses Rails’ Message Verifier module.
I learned about this from Kasper Timm Hansen.
Tokyo Ramen Street – Top 3 To Visit
https://www.5amramen.com/post/tokyo-ramen-streetWe had a chance to check out Tokyo Ramen Street in the basement of Tokyo Station.
For me, it was the dipping ramen at Rokurinsha. One of the best bowls of ramen I’ve had over the past 3 weeks. Great noodles, rich broth, ultra-savory thick cut of pork. Only complaint is that broth and noodles could have been hotter from the start as everything was lukewarm halfway through.
Access Control Syntax
https://journal.stuffwithstuff.com/2025/05/26/access-control-syntax/Munificent Bob breaks down the different ways that many languages manage access control for entities in modules. That is, how do I tell the parts of a program that import a module from somewhere else in the program what is private and what is public?
Big Problems From Big IN lists with Ruby on Rails and PostgreSQL
https://andyatkinson.com/big-problems-big-in-clauses-postgresql-ruby-on-railsI always enjoy these detailed PostgreSQL query explorations by Andrew.
I’ve seen this exact “big in clause” issue arise in many production Rails systems. These are tricky because the queries are often generated by ActiveRecord and they work fine for small data. As your data grows over time or specific power users do their thing, these sneaky, slow IN queries will start to crop up. Since they only happen some times, they often go unnoticed or appear hard to reproduce.
Andrew presents a lot of good options for rewriting these queries in a way that allows the database to better plan and optimize the query.
Spaced Repetition Systems Have Gotten Way Better
https://domenic.me/fsrs/I’ve used various learning platforms with spaced repetition built in, so I’m familiar with that concept. New to me is this new scheduling algorithm — Free Spaced Repetition Scheduler.
Commenters on the lobste.rs thread mentioned Ebisu as another learning scheduling resource.
Why some of us like "interdiff" code review systems (not GitHub)
https://gist.github.com/thoughtpolice/9c45287550a56b2047c6311fbadebed2I learned about git’s range-diff from this article which is useful if you adopt this interdiff approach of evolving patch series. Rather than doing additive commits in response to reviews and CI feedback.
This is the essence of "interdiff code review." You
- Don't publish new changes on top, you publish new versions
- You don't diff between the base branch and the tip of the developer's branch, you diff between versions of commits
- Now, reviewers get an incremental review process, while authors don't have to clutter the history with 30 "address review" noise commits.
- Your basic diagnostic tools work better, with a better signal-to-noise ratio.
Short alphanumeric pseudo random identifiers in Postgres
https://andyatkinson.com/generating-short-alphanumeric-public-id-postgresI’ve had to add this style of identifier to many apps that I’ve worked on, e.g. for something like coupon codes. I end up with a bespoke solution each time, usually in app code. It’s cool to see a robust solution like this at the database layer by adding a couple functions.
Claude and I write a utility program
https://blog.plover.com/tech/gpt/claude-xar.htmlJust In Time manual reading
The world is full of manuals, how can I decide which ones I should read? One way is to read them all, which used to work back when I was younger, but now I have more responsibilities and I don't have time to read the entire Python library reference including all the useless bits I will never use. But here's Claude pointing out to me that this is something I need to know about, now, today, and I should read this one. That is valuable knowledge.
TypeID is a spec
https://push.cx/typeid-in-luaI’ve always been a fan of the way Stripe does identifiers (e.g. cus_12345abcde for a customer). I was recently thinking about what it would look like to do something similar in my own app. This post made me aware that TypeID is what this sort of thing is called and that a spec exists.
Concurrent locks and MultiXacts in Postgres
https://blog.danslimmon.com/2023/12/11/concurrent-locks-and-multixacts-in-postgres/When multiple transactions have no exclusive locks on the same row, the database needs a way of tracking that set of transactions beyond the single xmax value that initially locks the row.
Postgres creates a MultiXact. A MultiXact essentially bundles together some set of transactions so that those transactions can all lock the same row at the same time. Instead of a transaction ID, a new MultiXact ID is written to the row’s xmax.
Esoteric Vim
https://freestingo.com/en/programming/articles/esoteric-vim/I love learning about the weird, arcane, dusty corners of vim, so this is a fun read.
Via this article on lobste.rs
Your words are wasted
https://www.hanselman.com/blog/your-words-are-wastedYou are not blogging enough. You are pouring your words into increasingly closed and often walled gardens. You are giving control - and sometimes ownership - of your content to social media companies that will SURELY fail.
I’m trying to write here more and link to things I read here more in this spirit of sharing more thoughts and publishing them in the open where I own them.
Don't Guess My Language
https://vitonsky.net/blog/2025/05/17/language-detection/Every browser sends an Accept-Language header. It tells you what language the user prefers, not based on location, not based on IP, based on their OS or browser config. And yes, users can tweak it if they care enough.
It looks like this: Accept-Language: en-US,en;q=0.9,de;q=0.8
That’s your signal, use it. It’s accurate, it’s free, it’s already there, no licensing, no guesswork, no maintenance.
As an example of when the location associated with an IP address is a reasonable heuristic: many course selling platforms use that to determine what if any Purchase Power Parity (PPP) discount to offer.
Japan’s IC Cards are weird and wonderful
https://aruarian.dance/blog/japan-ic-cards/It’s serendipitous that this article landed on the front page of lobste.rs as I’m in Japan for the first time this week and I’ve been using both a physical suica card and suica in iPhone wallet. I’m an avid CTA rider in chicago. I can easily tell how much faster these IC cards scan. I expect to have to stutter step as I scan to account for the delay, like on CTA, but these IC scanners are near instant.
Sync Engines
Over the last year or so I’ve seen several sync engines pop up as a paradigm shift in how we think about client and server data.
TanstackDB which is a generalized client but was built in partnership with ElectricSQL is described as:
A reactive client store for building super fast apps on sync
TanStack DB extends TanStack Query with collections, live queries and optimistic mutations that keep your UI reactive, consistent and blazing fast 🔥
Stop using REST for state synchronization
https://www.mbid.me/posts/stop-using-rest-for-state-synchronization/What struck me is how incredibly cumbersome, repetitive and brittle this programming model is, and I think much of this is due to using REST as interface between the client and the server. REST is a state transfer protocol, but we usually want to synchronize a piece of state between the client and the server. This mismatch means that we usually implement ad-hoc state synchronization on top of REST, and it turns out that this is not entirely trivial and actually incredibly cumbersome to get right.
Writing that changed how I think about PL
https://bernsteinbear.com/blog/pl-writing/I’m a big fan of these kinds of collections of blog posts and resources. The kind that I’m used to coming across is Essays on programming that I think about a lot.
turbopuffer
https://turbopuffer.com/docsturbopuffer is a fast search engine that combines vector and full-text search using object storage, making all your data easily searchable.
Turbopuffer is used by Cursor, Linear, Notion, and others to do improved search across large document sets by combining vector and FTS.
I learned about it from this article on how Cursor uses Merkle Trees for Indexing Your Codebase.
Reservoir Sampling
https://samwho.dev/reservoir-sampling/Reservoir sampling is a technique for selecting a fair random sample when you don't know the size of the set you're sampling from.
Should I Use A Carousel?
https://shouldiuseacarousel.com/The short answer is "no".
Want to read further? The site has a carousel you can click through with pull quotes from various studies done that have found them to be very ineffective.
via Sara Soueidan
CleanShot X and Retrobatch
https://leancrew.com/all-this/2025/01/cleanshot-x-and-retrobatch/Retrobatch (which I’m just now learning about) is a tool that appears to let you define pipelines of custom steps for processing images.
In this post, the author demonstrates a workflow (droplet?) for adding a background and drop shadow with CleanShot X and than trimming the edges down with Retrobatch.
This tool looks powerful as you can link shell, apple, etc. scripts into your workflows.
I came across this post while reading this one: https://bjb.dev/log/20250129-low-res-screenshots/
Rate Limiting Using the Token Bucket Algorithm
https://en.wikipedia.org/wiki/Token_bucketI was curious what it looked like to do metered access to a resource. Commonly when you talk about this topic, that resource is your own API that has a throughput ceiling. I was coming at this from the angle of an app with internal 3rd-party API calls that charge on a per-request basis. In that scenario I'd like to implement some level of spend control so that I don't wake up to a huge bill.
The Token Bucket Algorithm appears to be one common answer to this question.
Each consumer (maybe that is a user) of the app/API has a bucket of tokens and each token can be redeemed for one access of the limited resource. Each bucket can only fit so many tokens and you can decide how exactly you want to meter refilling the bucket. I think it is typically handled by periodically (e.g. "every X seconds") adding a token to each bucket that isn't full. The other extreme could be requiring a user to manually "refill" the bucket — i.e. recharge their account with more credits. Perhaps you may even want to mix in a heuristic that is guided by some global value like "% of max spend for the period."
I like the carnival analogy for the Token Bucket Algorithm described here: https://www.krakend.io/docs/throttling/token-bucket/#a-quick-analogy
Never lose a change again: Undo branches in Vim
https://advancedweb.hu/never-lose-a-change-again-undo-branches-in-vim/Vim uses a tree instead of a list when tracking your change history. That means even if you undo some changes and make a new change, you can still get back to the changes you originally undid. In a traditional editor/IDE with a list representation, that change would be lost.
This blog post has visuals to make it easier to understand the concept.
Notes, not a blog – David Crespo
https://crespo.business/posts/notes-not-a-blog/I’ve never managed to get a blog going, but I take a ton of notes for myself. So this time I’m trying the mental hack of calling these posts “notes” and writing about the most mundane things that could still be interesting to another person.
Same for me. Ever since I started writing “blogmarks” which have evolved more into what I’d consider notes, I find myself posting all the time. Whereas a blog post feels daunting, I get halfway through writing it, and then give up.
This is the rationale that has made it relatively easy for me to write so many TILs over the years.
BashMatic - BASH/DSL helpers for the rest of us.
https://bashmatic.dev/A powerful BASH framework with 900+ helper functions to make your BASH scripting easier, more enjoyable, awesome looking, and most importantly, fun.
With Claude lowering the barrier to try things out, I’ve been using it to write all kinds of one-off bash scripts to help with various day-to-day things. I notice common patterns arise and certain nice-to-haves that are missing. It made me wonder if there was a library of bash scripting utility functions. Sure enough. Very cool project!
Eisvogel Pandoc Template — GitHub
https://github.com/Wandmalfarbe/pandoc-latex-templateA clean pandoc LaTeX template to convert your markdown files to PDF or LaTeX. It is designed for lecture notes and exercises with a focus on computer science.
I've only ever generated super-bland PDFs from markdown using Pandoc. I'm pleasantly surprised to see that you can get such visually nice results starting from a markdown document (with some frontmatter).
I learned about this from Hans Schnedlitz's post of running Pandoc from Docker.
Bloom filters - Eli Bendersky
https://eli.thegreenplace.net/2025/bloom-filters/Great explanation, visuals, and implementation walkthrough in Go of Bloom Filters.
Fast(er) regular expression engines in Ruby
https://serpapi-com.cdn.ampproject.org/c/s/serpapi.com/blog/faster-regular-expression-engines-in-ruby/amp/A comparison of regular expression engines for Ruby — useful if you’re using regex at scale.
Grep by example: Interactive guide
https://antonz.org/grep-by-example/grep is the ultimate text search tool available on virtually all Linux machines. While there are now better alternatives (such as ripgrep), you will still often find yourself on a server where grep is the only search tool available. So it's nice to have a working knowledge of it.
There is a mini book, a playground, and interactive examples of practical ways to use grep.
Speaking in Tongues: PostgreSQL and Character Encodings
https://thebuild.com/blog/2024/10/27/speaking-in-tongues-postgresql-and-character-encodings/The character encoding decision is an easy one: Use UTF-8. Although one can argue endlessly over whether or not Unicode is the “perfect” way of encoding characters, we almost certainly will not get a better one in our lifetime, and it has become the de facto (and in many cases, such as JSON, the de jure) standard for text on modern systems.
Expand and Contract Pattern
The Expand and Contract pattern is a general database schema migration pattern to minimize locking and downtime that occurs when irreversibly modifying a production database schema. This is also known as the Parallel Change pattern.
Certain schema changes and operations can involve full table rewrites and other locking that cannot be tolerated by a system with production workloads. These can sneak up on us in production if we don't know about them because the same schema changes against non-production data may be instantaneous.
This pattern is necessary for something as simple as set not null on an existing column. You'd use this pattern to migrate a primary key from int to bigint. This would also be used for more complex operations like splitting out and normalizing a monolithic table to multiple tables or retroactively partitioning a table.
So, what is the "Expand and Contract" pattern?
There is no exact recipe. Each migration can require devising a custom approach. The general pattern holds and looks like this:
1. Expand the schema
Expand the existing schema to accommodate the "new" thing. This is often adding a new column or table which we will eventually swap to.
2. Sync write operations
Ensure write operations are kept in sync between the existing and "new" thing. This can either be handled by setting up database triggers now or by updating app code in the next step to write both places.
3. Expand application code interface
Update all application code to start writing to the "new" column or table. If you didn't set up triggers in the previous step, then you'll need the app code to also continue to write to the existing column or table.
4. Backfill new schema
Backfill the "new" column or table with all the existing data. Depending on the nature of the migration some sort of normalization or default value may need to be applied for certain records during this operation.
5. Cut reads over to new schema
At this point, the app is still reading from the existing schema. If this is an in-place migration, then this step may primarily be a transaction double-renaming so that the app is still referencing the same-named column or table, but in actuality is the "new" entity. The works if you're using triggers to stay in sync which you'll update or remove in this same transaction. Be more careful if the app is still writing both places.
Alternatively, you may opt for deploying app changes that cut all reads over to the new schema. No app code should read from the existing schema at this point, though some sync code may still be in place.
6. Ensure app works as expected
Beyond any automated testing that was enforced during previous steps, you'll want to thoroughly smoke test your app. It is now running on the new schema, reading migrated, backfilled data. Is everything looking good and checking out?
7. Remove writes to existing entities
If you haven't already, this is the time to remove any triggers or app code that are still syncing old and new entities now.
8. Contract the schema
We no longer need to old column or table that we started with. It is already growing out of date as our system continues to field write operations. The column or table can now be dropped.
And that's it. That's generally how to apply the Expand and Contract pattern.
Note: you should definitely take a backup before getting started with this work or more surgically, right before you cut reads over.
There is a great resource from Prisma on this as well: Using the expand and contract pattern | Prisma's Data Guide
What is a tool?
https://tante.cc/2025/04/27/are-ai-system-really-tools/This is a fun thought experiment. What is a tool? What distinguishes a tool from any object used in a make-shift way in place of a specific tool?
The author is making the argument that AI systems are not tools. I don’t find the argument compelling, but I do still think it opens up an interesting discussion. Here is the crux of their argument:
Tools are not just “things you can use in a way”, they are objects that have been designed with great intent for a set of specific problems, objects that through their design make their intended usage obvious and clear (specialized tools might require you to have a set of domain knowledge to have that clarity). In a way tools are a way to transfer knowledge: Knowledge about the problem and the solutions are embedded in the tool through the design of it.
Simon Willison has a good comment in the lobsters thread:
An LLM is a tool for turning input text that contains instructions into output text that follows those instructions.
If a laptop computer or a blank piece of paper is a tool, then an LLM is a tool. All three have an incredibly wide range of potential uses, many of which were never dreamed of by their creators.
If we aren’t allowed to call those “tools” then I guess we need a new word that describes them.
Via: lobsters
Flight rules for git
https://github.com/k88hudson/git-flight-rulesFlight Rules are the hard-earned body of knowledge recorded in manuals that list, step-by-step, what to do if X occurs, and why. Essentially, they are extremely detailed, scenario-specific standard operating procedures.
I’ve come across several comprehensive git resources and guides recently. In addition to this one:
Via: this Reddit response
In Defense of PostgreSQL MVCC and Vacuuming
https://www.softwareandbooz.com/in-defense-of-postgresql-mvcc-and-vacuuming/For all the FUD that gets spread about PostgreSQL’s MVCC architecture, its downsides are not impacting most users and the upsides are great.
Most of the complaints about the PostgreSQL implementation of MVCC revolve around vacuuming issues which can cause table bloat, transaction ID wraparound, and wasted overhead introduced by the visibility map.
From the Postgres docs:
The main advantage of using the MVCC model of concurrency control rather than locking is that in MVCC locks acquired for querying (reading) data do not conflict with locks acquired for writing data, and so reading never blocks writing and writing never blocks reading. PostgreSQL maintains this guarantee even when providing the strictest level of transaction isolation…
…proper use of MVCC will generally provide better performance than locks.
There are always tradeoffs. Someone being over-critical about the downsides of MVCC may not be representing what you lose when you switch away from Postgres.
The solution isn’t necessarily to jump ship, either. In other databases a large select statement can block your writes. You also won’t have a rich extension ecosystem or a complete vendor agnostic database.
Here are the kinds of things to learn about if you want to better understand how to tune your database for impacted workloads:
Talk about vacuum settings. Help people understand how to tune individual table thresholds. Discuss maintenanceworkmem, effective partitioning, and how to validate your settings with a given workload.
PostgreSQL Operations that can cause Table Rewrites
https://www.linkedin.com/posts/gwenshapira_table-rewrites-can-be-slow-and-disruptive-activity-7322327616135319552-ipFRFor example, doing a full vacuum rewrites a table. This is why tools like pg_repack exist, which help reduce the amount of locking.
See the post for the full table of operations.
Validate a startup idea with ruthless efficiency
https://open.substack.com/pub/michaeldrogalis/p/how-to-validate-a-startup-idea-withThe recurring idea in these steps is that you have to constantly be talking to people, find out what their pain is, if you can solve it, and if they’d actually pay for your solution. Then find more people and keep checking. Find out asap if you have enough critical mass to be successful.
Reduce locking caused by `set not null` with a check constraint
https://github.com/sbdchd/squawk/issues/300During Gülçin Yıldırım Jelínek's talk "Anatomy of Table-Level Locks in PostgreSQL", she mentioned that the common "Expand and Contract" schema migration approach to applying not null to an existing column will still involve an Access Exclusive table lock. This is because PostgreSQL needs to do a full table scan to ensure there are no instances of a null.
She goes on to mention that we can do better than that. We can further reduce locking with an additional step. If we first add an invalid not null check constraint for the column and eventually validate it after backfilling the entire table, then the alter table statement for adding the not null constraint will only need a Share Update Exclusive table lock. This means we can generally still perform SQL operations that read and update data.
According to the alter table docs:
SET NOT NULL may only be applied to a column provided none of the records in the table contain a NULL value for the column. Ordinarily this is checked during the ALTER TABLE by scanning the entire table; however, if a valid CHECK constraint is found which proves no NULL can exist, then the table scan is skipped.
Here is the relevant commit and commit message:
If existing CHECK or NOT NULL constraints preclude the presence
of nulls, we need not look to see whether any are present.
Which was added in the PostgreSQL 12 release.
This approach is also recommended by the strong_migrations gem for Rails.
Link Preview Meta Tags
https://getoutofmyhead.dev/link-preview-meta-tags/This page has a matrix of the different sets of meta tags and on which sites/apps those will display as part of a link preview (social card). There is quite a bit of mismatch between all of these. If you wanted to go with a single spec, it looks like Open Graph has the most comprehensive coverage across major apps.
Via lobsters
Backfill your blog
https://simonwillison.net/2025/Apr/25/backfill-your-blog/Fun fact: there's no rule that says you can't create a new blog today and backfill (and backdate) it with your writing from other platforms or sources, even going back many years.
I should probably skim back through my past tweets and see if I have some popular posts or under-developed ideas that could be turned into backfilled blog posts.
The most fabulous kind of machine
https://bertrandmeyer.com/2025/04/23/a-paean-to-programming/Now think about what computers really are: one of the most fabulous kind of machines ever devised by mankind, but different from all the machines invented before in that they can solve not just one problem, but any problem which is presented to them, provided the problem and the solution technique can be described in complete detaiI. A computer is thus more of a “meta-machine,” and computer science is really the science of problem-solving.
What happens when you add and remove a column from a table in Postgres
https://www.linkedin.com/posts/gwenshapira_what-happens-when-you-add-and-remove-a-column-activity-7320517353597718529-u_FiHere’s the question that Gwen poses:
What happens when you add and remove a column from a table in Postgres 2000 times?
I couldn’t come up with any good guesses.
The surprising answer is that PostgreSQL 1) has a hard limit of 1600 columns on any given table and 2) that removes columns are effectively soft-deleted. This means that each column you add to a table, regardless of whether it is later deleted, will contribute to that hard limit.
If you somehow run into this limit in a real-world database deployment (unlikely), you’ll have to swap everything into a new table to get around it.
Computers can be understood
https://blog.nelhage.com/post/computers-can-be-understood/any question I might care to ask (about computers) has a comprehensible answer which is accessible with determined exploration and learning.
The “with determined exploration and learning” is the important part here.
There is no magic. There is no layer beyond which we leave the realm of logic and executing instructions and encounter unknowable demons making arbitrary and capricious decisions. Most behaviors in one layer are comprehensible in terms of the concepts of the next layer, and all behaviors can be understood by digging down through enough layers.
Even recognizing and sorting out the different layers can be a great starting point. Then when you are thinking about a concept or issue, you can determine what layer is relevant to help set the context.
The trickiest bugs are often those that span multiple layers, or involve leaky abstraction boundaries between layers. These bugs are often impossible to understand at a single layer of the abstraction stack, and sometimes require the ability to view a behavior from multiple levels of abstractions at once to fully understand.
This tells us a lot about what we should strive for when trying to write clear, understandable code and whether we’ve done a good job when creating an abstraction.
Adopt a mindset of curiosity:
My advice for a practical upshot from this post would be: cultivate a deep sense of curiosity about the systems you work with. Ask questions about how they work, why they work that way, and how they were built.
… build your understanding, and your confidence that you can always understand more tomorrow.
My friend Jake Worth wrote his own version of this post — https://jakeworth.com/posts/computers-can-be-understood/
I think this is a great idea for any blogger. Take an inspiring or intriguing concept and give your own take on it.
Imposter Syndrome doesn’t go away
https://bsky.app/profile/jason.energy/post/3lndfufysx22ksomething I’ve learned about impostor syndrome is that it never goes away, but it gets less jarring, if that makes sense
it’s less “oh god everyone is going to find out I’m a fraud”
and more “oh god how am I still bad at this after all these years” but you know it’ll be fine in the end
Beej's Guide to Git
https://beej.us/guide/bggit/html/split/I’m still exploring this. It’s always interesting to see the in-depth details of how someone thinks about using a tool like git.
What I Wish Someone Told Me About Postgres
https://challahscript.com/what_i_wish_someone_told_me_about_postgresThe Postgres docs are massive, so “Read The Manual” is tough advice when getting started with it.
Except…Postgres. It’s not because the official docs aren’t stellar (they are!)–they’re just massive. For the current version (17 at the time of writing), if printed as a standard PDF on US letter-sized paper, it’s 3,200 pages long. It’s not something any junior engineer can just sit down and read start to finish.
This article breaks down a bunch of features and advice for getting into and using Postgres. It ranges from things like unintuitive NULL behavior, the Don’t Do This Postgres wiki, psql enhancements, and advice on indexes.
When in doubt, be consistent
https://google.github.io/styleguide/shellguide.htmlUsing one style consistently through our codebase lets us focus on other (more important) issues. Consistency also allows for automation. In many cases, rules that are attributed to “Be Consistent” boil down to “Just pick one and stop worrying about it”; the potential value of allowing flexibility on these points is outweighed by the cost of having people argue over them.
Lots of great tips in this style guide on writing good bash scripts.
Other good (general) advice:
When assessing the complexity of your code (e.g. to decide whether to switch languages) consider whether the code is easily maintainable by people other than its author.
Trigger recursion in PostgreSQL and how to deal with it
https://www.cybertec-postgresql.com/en/dealing-with-trigger-recursion-in-postgresql/This article walks through a couple examples of where infinite trigger recursion can happen if we’re not careful about when we’re updating and under what conditions.
I learned a few new things including the function for getting the current trigger depth and that a trigger definition can include a when clause so that it conditionally runs.
Great article, very approachable.
How to Understand a New Codebase Quickly
https://avdi.codes/how-to-understand-a-new-codebase-quickly/The best way I know to get acquainted with an unknown codebase is to fire it up locally (this alone may be very hard). Then approach softly, humbly, as a mere user. Start making theories about how it works, and what parts of the code are responsible for the behaviors you see.
This not only might be tricky to do, but you'll have to do it eventually anyway. You'll probably encounter several steps that are missing or aren't quite right. You can help with updating the docs where this setup slippage has occurred.
Then deliberately start breaking it.
This is a great idea. Make theories about what executes and how it executes. Then put it to the test with a little raise 'hell' here and there.
As you're approaching the app from the perspective of a user, think about the different kinds of users of the app and the unique workflows of each of those users. Also, are there important execution flows through the codebase that no user experiences or triggers, but instead are part of an external/automated process? Those flows can be hard to find and can be some of the most essential business logic.
When to use `--force-if-includes` with `git push`
https://stackoverflow.com/a/65839129/535590Every once in a while I stumble upon a wildly-thorough 2000+ word answer on StackOverflow. Most blog posts aren't this long, let alone SO answers. This is one of those answers.
So, you can try it out by using it for all
--force-with-leasepushes. All it does is use a different algorithm—one the Git folks are hoping will be more reliable, given the way humans are—to pick the hash ID for the atomic "swap out your branch name if this matches" operation that--force-with-leaseuses. You can do this manually by providing the=<refname>:<hash>part of--force-with-lease, but the goal is to do it automatically, in a safer way than the current automatic way.
The tl;dr is that you probably don't need this flag, but since it is marginally safer than only the --force-with-lease flag, you might consider using both just in case.
I guess this is why oh-my-zsh makes it the default for gpf for qualifying versions of git:
| gpf | On Git >= 2.30: git push --force-with-lease --force-if-includes
| gpf | On Git < 2.30: git push --force-with-lease
taste as a proxy for curiosity
https://www.misalignedmodel.com/posts/tasteEven if your current setup and workflows feel good enough, you might be stuck in a local maxima. It's not necessarily that there is anything wrong with that, but if you're curious, there could be more to unlock.
breaking out from your local maxima of productivity is hard. most power-user tools will slow you down at first. productivity gains will only come once you've mastered them
I too have had the experience of feeling like I'm always tweaking my vim config and dotfiles and other settings, endlessly, in pursuit of... I'm not sure what. It's good to know when to stop.
but taste is not about endless tweaking and chasing that perfect neovim config. knowing when to stop is a skill in itself
It's about finding a balance between sharpening your tools and a pragmatism that recognizes other priorities.
On the topic of customizing your dotfiles and keeping them version controlled somewhere, the author mentions GNU stow.
In Using GNU Stow to manage your dotfiles, how to use stow for dotfiles is demonstrated.
Some time ago I happened across a mailing list posting where someone described using Stow to manage the installation of their dotfiles. I didn’t pay much attention to it but my brain must have filed it away for later. Yesterday I decided to give it a try and I have to say that it is so much more convenient than those other dedicated dotfile-management programs, even if it wasn’t an immediately obvious option.
(All) Databases Are Just Files. Postgres Too
https://tselai.com/all-databases-are-just-filesThis is an intriguing simplification of how to think about what Postgres is and what it does:
At its core, postgres is simply a program that turns SQL queries into filesystem operations. A CREATE TABLE becomes a mkdir. An UPDATE eventually becomes: open a file, write to it, close it. It’s a complex and powerful system—but fundamentally, it’s just an executable that manipulates files.
Making the case for lifting the “veil of ignorance” and building up a mental model for how Postgres works:
Understanding how PostgreSQL actually works—how it’s started, where the files live, what the key binaries do—puts real power in your hands. It removes the mystery. It means you’re no longer just reacting when something breaks; you’re diagnosing, tweaking, even optimizing.
Vibe Coding the Right Way
https://wycats.substack.com/p/vibe-coding-the-right-wayTL;DR I use coding assistants to build out a piece of code. Once I feel ok with the initial output, I switch back into normal coding mode. I refactor the code, carefully document it and introduce abstractions that capture common patterns. I also write good tests for the code. For testing, I use my “normal coding brain” to come up with the test cases but lean on AI code accelerators to speed up the process.
I like this term AI code accelerators. It suggests that it helps do what you’d already decided to do. It helps with the boilerplate or repetition for instance.
I’m seeing more and more of this genre of article where very experienced software engineer describes their AI coding workflow.
Atoms (by brandur)
https://brandur.org/atomsAtoms are a cool variant of what I'm doing with blogmarks. tbh, it is closer to the format I want to be doing. I often have thoughts that aren't really tied to a specific blog post. Sometimes I have thoughts that bring together several blog posts or links.
Brandur describes Atoms as:
Multimedia particles in the style of a tweet, also serving as a changelog to consolidate changes elsewhere in the site. Frequently off topic.
Anyway, this one looks great and has good content.
It reminds me of Smidgeons. Though Maggie is more long-form with these as compared to Atoms.
Weaving Systems Together
http://geoffreylitt.com/2025/04/12/how-i-made-a-useful-ai-assistant-with-one-sqlite-table-and-a-handful-of-cron-jobs.htmlWhat I find fascinating by this article is less the idea of an “AI Assistant” and more the way a handful of tools can be weaved together into a useful personal tool.
Val.town acts as the glue for making requests to Claude and a SQLite database. It uses telegram as the UI where messages can be sent and received. It also connects to other systems like google calendar as well as being able to receive inbound emails.
Easy, alternative soft deletion: `deleted_record_insert`
https://brandur.org/fragments/deleted-record-insertThis is a simple (as in ‘not complex’) pattern for saving any deleted records that you want to persist in a shared, schemaless table. Triggers fire after delete for any table you want to save and that deleted data is inserted as a jsonb entry.
I suggest an alternative to deletedat called deletedrecord, a separate schemaless table that gets a full dump of deleted data, but which doesn’t interfere with mainline code (no need to include a deleted_at IS NULL predicate in every live query, no foreign key problems), and without the expectation that it’ll be used to undelete data.
This article is great, but it leaves me unsatisfied in that I don’t feel it touches on the “why” at all. Why and for what purpose are we saving the deleted data? Is it just for debugging purposes? Do we ever restore it or otherwise reference it?
Brandur also suggests that a simple deleted_at column won’t really work for undeleting data. Why not? This seems like the best method for that use case assuming you don’t mind all the implications for app code, queries, and indexes.
Brandur covers the reasons that undoing soft deletes isn’t as easy as it seems in Soft Deletion Probably Isn’t Worth It:
The biggest reason for this is that almost always, data deletion also has non-data side effects. Calls may have been made to foreign systems to archive records there, objects may have been removed in blob stores, or servers spun down. The process can’t simply be reversed by setting NULL on deleted_at – equivalent undos need to exist for all those other operations too, and they rarely do.
I came across the primary article (in the show notes) after listening to the Soft Deletes episode of Postgres.fm.
The Best Programmers
https://justin.searls.co/links/2025-04-14-the-best-programmers/Justin wrote this post in response to The Best Programmers I Know which was making the rounds last week.
Anyway, if you're asking me, the single best trait to predict whether I'm looking at a good programmer or a great one is undoubtedly perseverance. Someone that takes to each new challenge like a dog to a bone, and who struggles to sleep until the next obstacle is cleared.
Sometimes you run into a wall with a bug, you’ve searched for it a dozen different ways, you’ve talked off Claude’s ear about it, and you still don’t have a fix. How do you not give up when it feels this hopeless? That’s the perseverance he is talking about, at least in part.
For me, much of this perseverance is earned. Meaning, I pushed through to a solution when I was hopelessly stuck the last dozen times, so I know I can do it this time.
Ship Software That Does Nothing
https://kerrick.blog/articles/2025/ship-software-that-does-nothing/Shipping nothing is nothing to sneeze at. Delivering a blank page to production means you’ve made a lot of important decisions. You must take risky actions early, which is the best time to take risks. And once you’ve shipped software that does nothing, making it do something is easy.
It’s fun to read this article because I came to a similar conclusion recently with a couple side-projects. Typically with my side-projects I never get to the point where I’m ready to ship. So then, I simple don’t ever ship anything. They gather dust in that code directory on my machine.
However, with still and another recent project, one of the first things I did before there was any meaningful functionality was get them deployed to the public internet. Suddenly that unlocked this clarity where I knew what features to work on next and which ones to ignore because I was actually using the thing.
If you feel distracted, read this
https://michaeldrogalis.substack.com/p/if-you-want-to-go-long-term-you-needHidden goals are when you spend your time differently than what you said you wanted to do. At first glance, you might just call that being undisciplined. But it’s not the same.
I find this framing of hidden goals helpful. In period where I'm easily distractible, I'm pretty hard on myself. I berate myself, "why can't I be more focused, more disciplined with my time?" This gets closer to the truth of why I'm distracted. I have other goals, goals I haven't overtly acknowledged and they are pulling my focus from the thing I think I need to be devoting attention to at the moment. That's its own problem to work out, but at least it is less self-critical.
The article also gives some suggestions for how to navigate these times which all seem better than forcing yourself to push through it.
Introducing Zod 4 beta
https://v4.zod.dev/v4Several years in the making, Zod 4 is now in beta with a ton of performance improvements, bundle size improvements, and some new features.
Zod 4 is now in beta after over a year of active development. It's faster, slimmer, more tsc-efficient, and implements some long-requested features.
The things that caught my attention were:
- JSON Schema conversion -- this makes a schema serializable and portable to other contexts and even languages.
- Error Pretty Printing -- this is huge for dev server logs and scripting output because the errors are way more readable and don't completely blowout the terminal scroll back buffer.
- StringBool -- this seems nice for CLIs or JSON parsing where you know you're in a certain domain with specific truthy and falsy values
- Refinements and Overwrites -- the under-the-hood changes that allow refinements to be mixed in with other schema methods. Overwrites allow for same-type transformations that work with JSON schema conversion.
One of the headline features is Metadata and Schema Registeries which looks cool, but I can't see how I'd use it for anything I've done with Zod up to now. The best I can tell is that a library like OpenAPI or a form library would use it to essentially annotate a schema with additional metadata.
I've only mentioned a handful of the features, but the whole post is worth digging into. Matt Pocock also did an overview in Zod 4 is out, and it is CRAZY on his Youtube Channel.
Git Pathspecs and How to Use Them
https://css-tricks.com/git-pathspecs-and-how-to-use-them/Pathspecs are an integral part of many git commands, but their flexibility is not immediately accessible. By learning how to use wildcards and magic signatures you can multiply your command of the git command line.
I recently learned how to use a pathspec magic signature to exclude a directory from a git command.
$ git restore --patch -- . ':!spec/cassettes'
So, I was curious to learn more about this syntax, other magic signatures, and what all falls under the umbrella of a pathspec. I did some digging in the man pages and the main source of information I could find was a section on pathspec in the man gitglossary page. The descriptions here were fairly terse and didn't include examples.
Fortunately, Adam Giese wrote this excellent blog post on CSS Tricks covering the topic. It goes through everything from "what is a pathspec in its simplest form?" to "how to use the various magic signatures".
Here are two examples Adam gives of doing an exclude:
git grep 'foo' -- '*.js' ':(exclude)*.spec.js' # search .js files excluding .spec.js
git grep 'foo' -- '*.js' ':!*.spec.js' . # shorthand for the same
And here is an example of combining several magic signatures:
git ls-files -- ':(top,icase,glob,attr:!vendored)src/components/*/*.jsx'
Adam also pulled this amazing line from the man gitglossary page:
Glob magic is incompatible with literal magic.
Svelte teaching me about the Web Platform
One of the principles behind Svelte is to "Use the Platform". So, I wasn't too surprised while going through the Svelte Tutorial when I encountered a handy, new-to-me feature of the web platform, specifically in the JavaScript part of the platform.
The Multiple Select Bindings tutorial displays a list of ice cream flavors. It would have been easy to miss, but I noticed that as the number of selected flavors changed, the formatting changed.
Two items were separated by an and. More than two items became a comma-separated list with an and separating the last item from the rest. I think it caught my attention because I've implemented some version of this list formatting function numerous times across projects over the years. It also caught my attention because I hadn't noticed a function with the necessary chunk of logic to do that custom formatting.
I scrolled around to see what was responsible for the nice list formatting and found what I should have suspected from the get-go, an Intl formatter:
<script>
let scoops = $state(1);
let flavours = $state([]);
const formatter = new Intl.ListFormat('en', { style: 'long', type: 'conjunction' });
</script>
<!-- some lines of code elided -->
{:else}
<p>
You ordered {scoops} {scoops === 1 ? 'scoop' : 'scoops'}
of {formatter.format(flavours)}
</p>
{/if}
It's the Intl.ListFormat object that takes a list of items, some options, and a locale, and is able to nicely format a list as part of a sentence.
I cover this functionality in more detail in my latest TIL, Format a List of Items by Locale.
5 Hard Problems Companies May Need Consulting Help On for their PostgreSQL Databases
https://www.linkedin.com/posts/samokhvalov_postgresql-activity-7316278118468489216-h_qrNikolay points out some of the things that are uniquely hard and common challenges for many PostgreSQL databases. This means it is also a good list of things to demonstrate expertise in because companies will likely need consulting help with each of these.
Five hard problems in #PostgreSQL:
- LWLock contention of various kinds when various buffers overflow / thresholds exceeded
- no simple path to sharding for OLTP
- single-threaded processes (eg replication bottlenecks)
- partitioning requires a lot of effort
- upgrades too
I've done a number of PostgreSQL major version upgrades for companies. They are usually pretty uneventful because of how careful Postgres is with backward-compatibility. That said, they need to be carefully planned and executed to avoid or minimize downtime.
I explored partitioning with one client who had a massive events table. It is awkward and challenging to set up a partition after the fact. Ideally, you've designed the schema with partitioning from the start. In lieu of partitioning, we decided to do a swap-and-drop migration to remove hundreds of millions of old, unneeded rows.
Man pages are great, man readers are the problem
https://whynothugo.nl/journal/2025/04/09/man-pages-are-great-man-readers-are-the-problem/The author makes the point that while the file format for Man pages is great and can do a lot of things, the typical man page reader is lackluster.
We need better man page readers. Ones that let us follow references as links.
While I often use the default pager for quickly referencing a man page, I also really like to use the Man plugin for Vim / Neovim. Note: with Vim, the plugin is available, but needs to be enabled in your config (runtime ftplugin/man.vim). It's enabled by default in Neovim.
From a (Neo)vim session, I can open a specific man page with :Man like so:
:Man git-restore
From there, I'm in a mostly-standard read-only Vim buffer with the Man plugin providing a couple conveniences like color, link following, and hitting q to quit. At the same time, I can still do all kinds of Vim things like motions for quickly moving around and search to find occurrences of a specific word or pattern.
The big complaint of this article is that link following doesn't work. With Vim, we can move the cursor over a link and hit either K or Ctrl-] to follow it. And then you still get Vim navigation like Ctrl-o to jump back to the previous man page and cursor position.
We can also configure Neovim to be the default man pager on our system by adding the following to our shell config:
export MANPAGER='nvim +Man!'
This was recommended in the help file for the Man plugin (:h :Man).
I also noticed recently that Dash can slurp up all the man pages on your system to make them searchable and browsable. The man page links work in their docs browser.
Svelte Tutorial: "sparkling variable"
https://svelte.dev/tutorial/svelte/effectsThe Svelte tutorial is fantastic and has some nice bits of humor if you're paying attention.
state is only reactive if something is reacting to it, otherwise it’s just a sparkling variable.
LLM as contextual thesaurus for writing
https://bsky.app/profile/justinjackson.ca/post/3lmdjuld6lk2fJustin describes a use case for LLMs in writing, where he asked for the difference between "consumed" and "subsumed" and which would make more sense in what he is trying to say. The LLM gives definitions of both and suggests that "subsumed" is a better fit citing specifically why in the context of what is written.
I've done this and a similar thing where I'm trying to remember a word, it is on the tip of my tongue, so I describe what I'm trying to say and the LLM makes some suggestions. This can also be generally done for terms and phrases where you know the general idea but aren't sure what the technical term is.
Here is an example of this that I just did with Claude:
Me: "What do you call the kind of cognitive bias where you have already made up your mind, so as you engage in a shallow investigation, you key in to supporting evidence and ignore things that contradict your opinion?"
Claude:
This is known as confirmation bias. It's the tendency to search for, interpret, favor, and recall information in a way that confirms or supports your pre-existing beliefs or values, while giving less consideration to alternative possibilities or contradictory evidence.
When experiencing confirmation bias, people tend to:
- Selectively notice and emphasize evidence that supports their existing belief
- Discount or ignore evidence that contradicts their view
- Interpret ambiguous information in ways that reinforce their position
- Seek out sources that align with their perspective
It's one of the most well-documented cognitive biases and affects people across many domains, including politics, personal relationships, scientific research, and everyday decision-making. Confirmation bias can be particularly problematic because it creates a self-reinforcing cycle that makes it difficult to change one's mind even when presented with new, relevant information.
GitHub - dylanaraps/pure-bash-bible
https://github.com/dylanaraps/pure-bash-bibleThe goal of this book is to document commonly-known and lesser-known methods of doing various tasks using only built-in bash features. Using the snippets from this bible can help remove unneeded dependencies from scripts and in most cases make them faster.
I learned about this via Can anyone suggest me good Bash book filled with small examples only? : r/bash.
Other recommendations in that thread:
- BashGuide - Greg's Wiki
- Advanced Bash-Scripting Guide (note: there are comments that warn people away from this guide because it has errors that the author won't respond to)
One does not simply update one's dependencies
https://rosswintle.uk/2025/04/one-does-not-simply-update-ones-dependencies/It’s a fun thought experiment to look at a particular slice of your day-to-day job as a software dev and spin out all the layers and tangential things you need to know to make sense of that thing and do that thing.
Some fun ones to spin out would be:
- reviewing a pull request
- tracking down a bug in production
- “shipping” a feature
good inventions have infinite pathways leading to them
https://bsky.app/profile/danabra.mov/post/3lm6edcv2e226Quoting Dan Abramov
how something was invented is entertaining but not necessarily educational. i like to teach a fictional account of inventions where the inventor is you, the reader. good inventions have infinite pathways leading to them, and some are simpler than others. a case of fiction being truer than history
Random PostgreSQL Scripts
https://github.com/lesovsky/uber-scripts- uber-scripts - https://github.com/lesovsky/uber-scripts
- postgres_dba - https://github.com/NikolayS/postgres_dba
- HandySQL - https://github.com/davestokes/HandySQL
Wait a minute! — PostgreSQL extension pg_wait_sampling
https://andyatkinson.com/blog/2024/07/23/postgresql-extension-pg_wait_samplingThe pg_wait_sampling extension is a handy companion to pg_stat_statements and pg_locks, providing historical samplings of wait events. This helps with tracking down queries that block one and other causing contention in your database.
Things That Aren’t Doing The Thing
https://strangestloop.io/essays/things-that-arent-doing-the-thingThe only thing that is doing the thing is doing the thing.
Horseless intelligence
https://nedbatchelder.com/blog/202503/horseless_intelligence.htmlMy advice about using AI is simple: use AI as an assistant, not an expert, and use it judiciously. Some people will object, “but AI can be wrong!” Yes, and so can the internet in general, but no one now recommends avoiding online resources because they can be wrong. They recommend taking it all with a grain of salt and being careful. That’s what you should do with AI help as well.
Skeptics of the uses of LLMs typically point to strawman arguments and gotchas to wholesale discredit LLMs*. They're either clinging too tightly to their bias against these tools or completely missing the point. These tools are immensely useful. They aren't magic boxes though, despite what the hypemen might want you to believe. If you take a little extra effort to use them well, they are a versatile swiss army knife to add to your software tool belt."Use [these LLMs] as an assistant, not an expert."
*There are soooo many criticisms and concerns we can and should raise about LLMs. Let's have those conversations. But if all you're doing is saying, "Look, I asked it an obvious question that I know the answer to and it got it WRONG! Ha, see, this AI stuff is a joke." The only thing you're adding to the dialogue is a concern for your critical thinking skills.
If you approach AI thinking that it will hallucinate and be wrong, and then discard it as soon as it does, you are falling victim to confirmation bias. Yes, AI will be wrong sometimes. That doesn’t mean it is useless. It means you have to use it carefully.
Use it carefully, and use it for what it is good at.
For instance, it can scaffold a 98% solution to a bash script that does something really useful for me. Something that I might have taken an hour to write myself or something I would have spent just as much time doing manually.
Another instance, I'm about to write a couple lines of code to do X. I've done something like X before, I have an idea of how to approach it. A habit I've developed that enriches my programming life is to prompt Claude or Cursor for a couple approaches to X. I see how those compare to what I was about to do.
There are typically a few valuable things I get from doing this:
- The effort of putting thoughts into words to make the prompt clarifies my thinking about the problem itself. Maybe I notice an aspect of it I hadn't before. Maybe I have a few sentences that I can repurpose as part of a PR description later.
- The LLM suggests approaches I hadn't considered. Maybe it suggests a command, function, or language feature I don't know much about. I go look those things up and learn something I wouldn't have otherwise encountered.
- The LLM often draws my attention to edge cases and other considerations I hadn't thought of when initially thinking through a solution. This leads me to develop more complete and robust solutions.
I’ve used AI to help me write code when I didn’t know how to get started because it needed more research than I could afford at the moment. The AI didn’t produce finished code, but it got me going in the right direction, and iterating with it got me to working code.
Sometimes you're staring at a blank page. The LLM can be the first one to toss out an idea to get things moving. It can get you to that first prototype that you throw away once you've wrapped your head around the problem space.
Your workflow probably has steps where AI can help you. It’s not a magic bullet, it’s a tool that you have to learn how to use.
This reiterates points I made above. Approach LLMs with an open and critical mind, give it a chance to see where they can fit into your workflow.
Git Pulled What???
https://frankwiles.com/posts/two-handy-git-aliases/Usually when I'm doing a git command that involves a ref of the form @{1}, it is because I'm targeting a specific entry in the reflog that I want to restore my state to.
Frank points out another use for these right after pulling down the latest changes from a remote branch.
This will display all the commits that were pulled in from the latest pull (e.g. git pull --rebase):
$ git log @{1}..
And this will show a diff of all the changes between where you just were and what was just pulled in:
$ git diff @{1}..
One thing to keep in mind is to be sure that you are using @{1} immediately after you pull. Any other things you might do, such as changing branches, will put another entry on the reflog making @{1} no longer reference your pre-pull state.
In that case, you'd need to do git reflog and find what entry does correspond to right before you pulled.
There is no Vibe Engineering
https://serce.me/posts/2025-31-03-there-is-no-vibe-engineeringSoftware engineering is programming integrated over time. The integrated over time part is crucial. It highlights that software engineering isn't simply writing a functioning program but building a system that successfully serves the needs, can scale to the demand, and is able to evolve over its complete lifespan.
LLMs generate point-in-time code artifacts. This is only a small part of engineering software systems over time.
Vibe Coding as a practice is here to stay. It works, and it solves real-world problems – getting you from zero to a working prototype in hours. Yet, at the moment, it isn’t suitable for building production-grade software.
List of all ShellCheck Rules
https://www.shellcheck.net/wiki/This is the root wiki page for ShellCheck which lists all of the rules that it enforces when checking your scripts.
Each rule links to a page that describes the issue, shows you an example of the problematic code, and a corrected version.
E.g. SC1003 Want to escape a single quote? echo 'This is how it'\''s done.' shows:
Problematic code:
echo 'this is not how it\'s done'
Corrected code:
echo 'this is how it'\''s done'
Programming is about mental stack management
https://justin.searls.co/posts/programming-is-about-mental-stack-management/Humans, like LLMs, have a context window too.
Fun fact: humans are basically the same. Harder problems demand higher mental capacity. When you can't hold everything in your head at once, you can't consider every what-if and, in turn, won't be able to preempt would-be issues. Multi-faceted tasks also require clear focus to doggedly pursue the problem that needs to be solved, as distractions will deplete one's cognitive ability.
What usually happens when we get too much context for the problem at hand is that we start to lose track of details, we get distracted, maybe even irritable. The task and the time it takes to do it balloon. We might even forgot why we start down this path in the first place.
As I was reading Justin’s example of the mental task stack he ended up down, I thought it sounded farfetched. “No one is going to do all these unnecessary things when they are just trying to add a route.” But then I remembered ALL the times that I get six steps removed from what I set out to do because of a series of unexpected mishaps and several “I can’t help myself”s.
Chesterton's Fence: Understanding past decisions
https://thoughtbot.com/blog/chestertons-fenceThere exists in such a case a certain institution or law; let us say, for the sake of simplicity, a fence or gate erected across a road. The more modern type of reformer goes gaily up to it and says, “I don’t see the use of this; let us clear it away.” To which the more intelligent type of reformer will do well to answer: “If you don’t see the use of it, I certainly won’t let you clear it away. Go away and think. Then, when you can come back and tell me that you do see the use of it, I may allow you to destroy it.”
I’ve often seen this concept used to talk about rashly throwing things away in a software development context. Anything from a misunderstood conditional check to an entire piece of infrastructure. “This doesn’t make sense, let’s refactor it.” Make it make sense first!
This is part of why I’m very cautious when it comes to refactoring legacy code. I’d much rather avoid the temptation of a few cathartic refactors while fixing some bug and avoid the pain of later finding out I broke a narrow use case.
It’s just as applicable to any setting/field where a (over-)confident person sees a policy, practice, or even something physical like a fence and is ready to get rid of it without understanding why it is there.
Hermitage (GitHub) — Test Suite for DB Isolation Levels
https://github.com/ept/hermitageIsolation looks a little different in every database system. This is a test suite for many popular databases to demonstrate what the mean by each of their isolation levels.
Isolation is the I in ACID, and it describes how a database protects an application from concurrency problems (race conditions). If you read a traditional database theory textbook, it will tell you that isolation is supposed to mean serializability, i.e. you can pretend that transactions are executed one after another, and concurrency problems do not happen. However, if you look at the implementations of isolation in practice, you see that serializability is rarely used, and some popular databases (such as Oracle) don't even implement it.
Conway's Law
https://martinfowler.com/bliki/ConwaysLaw.htmlAny organization that designs a system (defined broadly) will produce a design whose structure is a copy of the organization's communication structure.
Or put another way as I’ve also seen this concept described:
Organizations design systems that mirror their own communication structures.
Fowler gives a concise example of what this can look like.
if a single team writes a compiler, it will be a one-pass compiler, but if the team is divided into two, then it will be a two-pass compiler.
It’s not that there is a wrong or right way for an organization to communicate, but rather that an organization should ensure there isn’t dissonance between communication structures and system design.
We often see how inattention to the law can twist system architectures. If an architecture is designed at odds with the development organization's structure, then tensions appear in the software structure. Module interactions that were designed to be straightforward become complicated, because the teams responsible for them don't work together well.
I was reminded of Conway’s Law because it was mentioned in Pierre’s new landing page.
Nuclear Daiquiri 🍹
https://www.reddit.com/r/cocktails/s/DqkqxTJnmgA riff on the classic daiquiri that incorporates Falernum and Green Chartreuse. I’ve made this at home once but we subbed (Faccia Brutto) Centerbe for the Green Chartreuse.
The chartreuse gives it a green hue hence the nuclear part.
- 1oz Wray and Nephew Overproof Rum
- 1oz lime juice
- .75oz green chartreuse
- .25oz falernum
Shake with ice, double strain into a coup.
Semantic Diffusion
https://martinfowler.com/bliki/SemanticDiffusion.htmlI learned this term just now from Simon Willison who quoted the following from Martin Fowler:
Semantic diffusion occurs when you have a word that is coined by a person or group, often with a pretty good definition, but then gets spread through the wider community in a way that weakens that definition. This weakening risks losing the definition entirely - and with it any usefulness to the term.
While Simon is lamenting the diffusion of the meaning of Vibe Coding, Martin, back in 2006, was seeing this happen with terms like Agile and Web2.0.
Semantic diffusion is essentially a succession of the telephone game where a different group of people to the originators of a term start talking about it without being careful about following the original definition. These people are listened to by a further group which then goes on to add their own distortions. After a few of these hand-offs it's easy to lose a lot of the key meaning of the term unless you make the point of going back to the originators. It's ironic that it's popular terms that tend to suffer from this the most. That's inevitable, of course, since unpopular terms have less people to create the telephone chains.
Hope is not lost though.
So terms do recover their semantic integrity and the current diffusion doesn't inevitably mean the terms will lose their meaning… A final comforting thought is that once the equally inevitable backlash comes we get a refocusing on the original meaning.
So once the hype dies down, the broader understanding of vibe coding may settle back on the kind of coding:
where you fully give in to the vibes, embrace exponentials, and forget that the code even exists… It's not too bad for throwaway weekend projects.
Next.js vs TanStack
https://www.kylegill.com/essays/next-vs-tanstack/I’ve only heard good things about TanStack (Start) and have been wanting to try it. This post may be the encouragement I need.
With Next.js, a combination of the push for the App router and the move to RSC shattered the original simplicity of React.
The app router is riddled with footguns and new APIs, unrelated to React, but sometimes blurring the line with it. It’s hard to know when Next.js begins, and React ends.
Writing Beyond the Academy
https://www.youtube.com/watch?v=aFwVf5a3pZMYou should strive for your writing to be four things:
- Clear
- Organized
- Persuasive
- Valuable
And it is valuable that is the most important
Anytime you want to apply any sort of rule to your writing, you should be asking, "for which readers, and what purpose?"
- "Don't use jargon" ... maybe (probably not), but if so, be able to answer, "for which readers and what purpose?"
- "Use short sentences." ... well, for who and why?
No advice about writing makes any sense unless you've clarified who is reading and for what function.
Claim: the function of the text is change the way the readers think about the _world. You are a person with expertise, who spends time thinking and writing nuanced, complex, interesting, deep things in your area and how it relates to the world. What your write, the text, is the readers experience of that. Whether it is valuable to them depends on whether what you have written valuably changes what they think about the world (or what they do out in the world/in their job/in their life, or how they make decisions out in the ..., etc.).
Or to change the perspective on that: good writing is something that people will seek out (pay for even) because they want to read something that will change the way they think about the world.
Readers need you to make your text valuable to them. Instead of "does your writing check these boxes and follow these rules?" it is "does your writing provide value that readers are seeking?".
Larry strongly emphasizes the point that teachers throughout all of your years of education read what you had to write not because the writing was valuable to them, but because it was valuable to them that they were paid to read what you wrote and evaluate you for it. He goes on to say, this will never happen again after school, no one will be paid to read what you write. This isn't quite right though. There are a lot of jobs where a person doesn't have to be good at writing because everyone on their team (or on the project or whatever) is expected (and paid) to read it -- a report, documentation, a plan for a project, an email, etc. These things can be as well-written or poorly-written as you can imagine and we have to read them. Well-run and poorly-run meetings function the same way.
"the language game"
Why do people read something like the NYT? To be informed...maybe. But also, perhaps primarily, it is to be entertained. The editors at the NYT understand that.
You have to think about this holistically, which means you have to think about the reader, how they are encountering the text, and what their experience of it is. Once you are looking at it through that lens, you can notice the ways in which the medium gets in the way of the reader or enables the reader... to get the value they are seeking.
In what ways can the medium (text, content, whatever) interfere with the process of consumption (reading, viewing, whatever)?
Your job, as a writer, is to make sure the process of reading is valuable for the reader... all the time.
The importance of knowing your audience is knowing what they'll endure to get to the valuable part. If, in the case of the average NYT, it is "not much" that they will endure, then you need to provide constant value (whether that is quick-hitting sentences OR long sentences with value laced within). What you cannot do in that case is make them wait until the end to get the value, because they won't get there. You'll lose them before that. They quit, they read something else. That might work in an academic paper where the reader is willing to wait until the end of a dense paragraph, but that is a different language game.
did u ever read so hard u accidentally wrote?
https://blog.danslimmon.com/2025/03/14/did-u-ever-read-so-hard-u-accidentally-wrote/Reads (selects) won’t modify rows, but because of the internal bookkeeping that Postgres does, it can result in metadata that the WAL needs to write out to pages on disk. So in that sense, reads can result in writes.
This is such a relatable conclusion that echos many of my experiences chasing down odd production bugs:
Ops is like this a lot of the time. Once you get a working fix, you move on to whatever’s the next biggest source of anxiety. Sometimes you never get a fully satisfying “why.” But you can still love the chase.
Also, yes, Cybertec is always on top of it. One of the best in-depth Postgres blogs out there.
So I resort to Googling around for a while. I eventually land on this Cybertec blog post (there’s always a Cybertec post. God bless ’em), which demystifies shared buffers for me.
Claude Code - Anthropic
https://docs.anthropic.com/en/docs/agents-and-tools/claude-code/overviewI'm giving Claude Code a try. It is a terminal-based LLM agent that can iterate on software tasks with a human in the loop to prompt a task description, confirm or abort individual actions, and guide the process.
Claude Code does usage-based metering. As I'm currently looking at the "Buy Credits" page, there is an initial billing limit of $100 per month:
All new accounts have a monthly limit of $100 credits/month. This limit increases with usage over time.
After purchasing credits, I'm presented with a hero section large font that says:
Build something great
Once logged in to Claude Code in the terminal, I am first shown the following security notes:
Security notes:
1. Claude Code is currently in research preview
This beta version may have limitations or unexpected behaviors.
Run /bug at any time to report issues.
2. Claude can make mistakes
You should always review Claude's responses, especially when
running code.
3. Due to prompt injection risks, only use it with code you trust
For more details see:
https://docs.anthropic.com/s/claude-code-security
Why You Need Strong Parameters in Rails
https://www.writesoftwarewell.com/why-use-strong-parameters-in-rails/This includes an interesting bit of history about a GitHub hack that inspired the need for strong parameters in Rails.
If you want to see a real-world example, in 2012 GitHub was compromised by this vulnerability. A GitHub user used mass assignment that gave him administrator privileges to none other than the Ruby on Rails project.
The article goes on to demonstrate the basics of using strong params. It even shows off a new-to-me expect method that was added in Rails 8 that is more ergonomic than the require/permit syntax.
# require/permit
user_params = params.require(:user).permit(:name, :location)
# expect
user_params = params.expect(user: [:name, :location])
Quoting Dave Rupert
https://daverupert.com/2025/03/enshittification-has-a-flavor/Going forward, I think taste and style are more valuable than ever before. In an era where we’re able to rapidly generate cheap low quality content or software at a scale we’ve never seen before, we will need people with taste in the mix.
Release and EoL calendars for Amazon RDS for PostgreSQL
https://docs.aws.amazon.com/AmazonRDS/latest/PostgreSQLReleaseNotes/postgresql-release-calendar.htmlAWS maintains a nice table of both the Community End of Life and RDS End of Standard Support dates for major versions of PostgreSQL. I had trouble finding this info all in a single place elsewhere.
PostgreSQL has an official page documenting their versioning policy and when the first and last release dates of each major version were. This doesn't include community end of life dates though.
The 70% problem: Hard truths about AI-assisted coding
https://addyo.substack.com/p/the-70-problem-hard-truths-aboutLLMs are no substitute for the hard-won expertise of years of building software, working within software teams, and evolving systems. You can squeeze the most out of iterations with a coding LLM by bringing that experience to every step of the conversation.
In other words, they're applying years of hard-won engineering wisdom to shape and constrain the AI's output. The AI is accelerating their implementation, but their expertise is what keeps the code maintainable.
The 70% problem
A tweet that recently caught my eye perfectly captures what I've been observing in the field: Non-engineers using AI for coding find themselves hitting a frustrating wall. They can get 70% of the way there surprisingly quickly, but that final 30% becomes an exercise in diminishing returns.
Addy goes on to describe this "two steps back pattern" where a developer using an LLM encounters an error, they ask the LLM to suggest a fix, the fix sorta works but two other issues crop up, and repeat.
This cycle is particularly painful for non-engineers because they lack the mental models to understand what's actually going wrong. When an experienced developer encounters a bug, they can reason about potential causes and solutions based on years of pattern recognition.
Beyond having the general programming and debugging experience to expedite this cycle, there is also an LLM intuition to be developed. I remember John Lindquist describing that he notices certain "smells" when working with LLMs. For instance, often when you're a couple steps into a debugging cycle with an LLM and it starts wanting to go make changes to config files, that is a smell. It's a "smell" because it should catch your attention and scrutiny. A lot of times this means the LLM is way off course and it is now throwing generative spaghetti at the wall. I learned two useful things from John through this:
- You have to spend a lot of time using different models and LLM tools to build up your intuition for these "smells".
- When you notice one of these smells, it's likely that the LLM doesn't have enough or the right context. Abort the conversation, refine the context and prompt, and try again. Or feed what you've tried into another model (perhaps a more powerful reasoning one) and see where that gets you.
Being able to do any of that generally hinges on having already spent many, many years debugging software and having already developed some intuitions for what is a good next step and what is likely heading toward a dead end.
These LLM tools have shown to be super impressive at specific tasks, so it is tempting to generalize their utility to all of software engineering. However, at least for now, we should recognize the specific things they are good at and use them for that:
This "70% problem" suggests that current AI coding tools are best viewed as:
- Prototyping accelerators for experienced developers
- Learning aids for those committed to understanding development
- MVP generators for validating ideas quickly
I'd at to this list:
- Apply context-aware boilerplate autocomplete — establish a pattern in a file/codebase or rely on existing library conventions and a tool like Cursor will often suggest an autocompletion that saves a bunch of tedious typing.
- Scaffold narrow feature slices in a high-convention framework or library — Rails codebases are a great example of this where the ecosystem has developed strong conventions that span files and directories. The LLM can generate 90% of what is needed, following those conventions. By providing specific rules about how you develop in that ecosystem and a tightly defined feature prompt, the LLM will produce a small diff of changes that you can quickly assess and test for correctness. To me this is distinct from the prototyping item suggested by Addy because it is a pattern for working in an existing codebase.
Now you don’t even need code to be a programmer. But you do still need expertise
https://www.theguardian.com/technology/2025/mar/16/ai-software-coding-programmer-expertise-jobs-threatThis quote about Simon is spot on and it is why I recommend his blog whenever I talk to another developer who is worried about LLM/AI advancement.
A leading light in this area is Simon Willison, an uber-geek who has been thinking and experimenting with LLMs ever since their appearance, and has become an indispensable guide for informed analysis of the technology. He has been working with AI co-pilots for ever, and his website is a mine of insights on what he has learned on the way. His detailed guide to how he uses LLMs to help him write code should be required reading for anyone seeking to use the technology as a way of augmenting their own capabilities. And he regularly comes up with fresh perspectives on some of the tired tropes that litter the discourse about AI at the moment.
It is tough to wade through both the hype and the doom while trying to keep tabs on "the latest in AI". Simon has an excitement for this stuff, but it is always balanced, realistic, and thoughtful.
The author then goes on to quote Tim O'Reilly on the subject of "what does this mean for programming jobs?"
As Tim O’Reilly, the veteran observer of the technology industry, puts it, AI will not replace programmers, but it will transform their jobs.
Which compliments the sentiment from Laurie Voss' latest post AI's effects on programming jobs which expects we will see a lot more programming jobs in the wake of an LLM transformation of the industry.
And as my friend Eric suggested, the Jevons Paradox may come in to play where programmers are the "resource" being more efficiently consumed which will, paradoxically, increase the demand for programmers.
AI's effects on programming jobs
https://seldo.com/posts/ai-effect-on-programming-jobsI would like to advance a third option, which is that AI will create many, many more programmers, and new programming jobs will look different.
What do we call the emerging type of programming job where a person is instructing or orchestrating AIs and LLMs to do work while not necessarily knowing the lower level details (code)?
Including "AI" in the name feels wrong though, it's got a horseless carriage feel. All programming will involve AI, so including it in the name will be redundant.
The statement “All programming will include AI.” caught me attention. It seems like an optional, even niche tool at the moment. The prediction here being that it will become ubiquitous, perhaps to the same degree as using an IDE or to using auto code formatters.
I find myself and lots of others pondering on the impact of LLMs on software development to want to generalize to one big brush stroke, but I think the reality is going to be closer to what is described here.
I think we will see all three at the same time. Some AI-assisted software development will raise the bar for quality to previously cost-ineffective heights. Some AI-driven software will be the bare minimum, put together by people who could never have successfully written software before. And a great deal will be software of roughly the quality we see already, produced in less time, and in correspondingly greater quantity.
The general sentiment of this post is that there will be more jobs, not fewer. And that the impact on salaries (existing ones at least) won’t be much.
Some words of caution though:
But the adjustment won't be without pain: some shitty software will get shipped before we figure out how to put guardrails around AI-driven development. Some programmers who are currently shipping mediocre software will find themselves replaced by newer, faster, AI-assisted developers before they manage to learn AI tools themselves. Everyone will have a lot of learning to do. But what else is new? Software development has always evolved rapidly. Embrace change, and you'll be fine.
Via Seldo on Bluesky
LLMs amplify existing technical decisions
https://bsky.app/profile/nateberkopec.bsky.social/post/3lkj4kp53gt2pIf you’ve made sustainable decisions and developed good patterns, LLMs can amplify those. If you’ve made poor technical decisions, LLMs will propagate that technical debt.
Technical debt accumulates when people just "glob on" one more thing to an existing bad technical decision.
We chicken out and ship 1 story point, not the 10 it would take to tidy up.
LLMs encourage this even more. See thing, make more of thing. Early choices get copied.
xkcd: Nerd Sniping
https://xkcd.com/356/I’m not sure that the term “nerd sniping” was coined by XKCD, but this seems like as good a reference as any.
“Mountain” Drill 🎱
https://www.instagram.com/reel/DHOT7GSO9aS/?igsh=emFmZ2I1c3hhajRkThis is a challenging drill for practicing moving the ball across the width of the table using the long rails with small adjustments in english on somewhat steep cut shots.
A pitch for jujutsu
https://lobste.rs/s/ozgd5s/can_we_communally_deprecate_git_checkout#c_icfohkjujutsu -- a version control system
I think what’s remarkable about Jujutsu is that it makes all those slightly exotic git workflows both normal and easy.
They go on to describe all these common git mechanics that jj makes more accessible.
Jujutsu simplifies the UX around those operations significantly, and makes some changes to the git model to make them more natural. Squash has its own command, splitting a commit into two is a first-class operation, rebase only does what the name suggests it should, and you can go back to any previous commit and edit it directly without any ceremony. Jujutsu also highlights the unique prefix of commit/change IDs in its UI, which is a small UI change but it makes it much easier to directly address change IDs because you only have to type a few characters instead of copying and pasting 40 characters. If you run into a conflict during any of these operations you don’t have to fix it right away like git: they sit in the history and you can deal with them however you want.
And a comment right below this points out that because of jj's interoperability with git, you can collocate to start using jj in an existing git project right away.
My only advice to someone truly curious about jj is to drop into any code base you’re familiar with, jj git init --colocate, and work for week only using jj. It won’t be painful. You’ll occasionally be unfamiliar with how to achieve some workflow with jj, but the docs are good and you’ll figure it out.
The Japanese Grammar Index
https://www.tofugu.com/japanese-grammar/Someone on bluesky recommended this as a good supplement to other Japanese language learning resources.
These hubs connect grammar concepts to give you a deeper understanding of how Japanese works. Learn the ins and outs of Japanese word types, conjugations and forms, and how culture affects communication.
In the same thread, Tae Kim's Guide to Japanese was mentioned as well.
Dan Abramov, the OP, also recommended using Kana on iOS for practicing Hiragana and Katakana.
Understanding the bin, sbin, usr/bin, usr/sbin split
https://lists.busybox.net/pipermail/busybox/2010-December/074114.htmlI guess there is a discussion that floats around the internet every once and a while that attempts to backronym the/usr directory as unix system resources directory when really it is just what Ken Thompson and Dennis Richie called the bucket for all user space directories when they mounted a second drive.
The /bin vs /usr/bin split (and all the others) is an artifact of this, a
1970's implementation detail that got carried forward for decades by
bureaucrats who never question why they're doing things.
The whole listserv message is a good history of how these directories came to be and how bureaucracy has propagated that forward.
Squeeze the hell out of the system you have, by Dan Slimmon
https://blog.danslimmon.com/2023/08/11/squeeze-the-hell-out-of-the-system-you-have/This article is great because it gets at the higher-level thinking that engineering leads and CTOs need to bring to the table when your team is making high-impact technical decisions.
Anyone who has been in the industry a bit can throw around the pithy phrases we use to sway approval toward the decision we're pitching, e.g. "micro-services allow us to use the right tool for the job".
That can be a compelling argument alone if the stakes are low or we're not paying attention.
The higher-level thinking that needs to come in looks beyond the lists of Pros that we can make for any reasonable item that is put forward.
We have to have an understanding of tradeoffs and a more holistic sense of the costs.
But don’t just consider the implementation cost. The real cost of increased complexity – often the much larger cost – is attention.
The attention cost is an ongoing cost.
[Clever solution that adds complexity] complicates every subsequent technical decision.
Squeeze what you can out of the system, buying time, until you have to make a concession to complexity.
When complexity leaps are on the table, there’s usually also an opportunity to squeeze some extra juice out of the system you have.
because we squeezed first, we get to keep working with the most boring system possible.
Here’s how I use LLMs to help me write code
https://simonwillison.net/2025/Mar/11/using-llms-for-code/There are a bunch of great tips in here for getting better use out of LLMs for code generation and debugging.
The best way to learn LLMs is to play with them. Throwing absurd ideas at them and vibe-coding until they almost sort-of work is a genuinely useful way to accelerate the rate at which you build intuition for what works and what doesn't.
LLMs are no replacement for human intuition and experience. I've spent enough time with GitHub Actions that I know what kind of things to look for, and in this case it was faster for me to step in and finish the project rather than keep on trying to get there with prompts.
GitHub - yamadashy/repomix: 📦 Repomix
https://github.com/yamadashy/repomix📦 Repomix (formerly Repopack) is a powerful tool that packs your entire repository into a single, AI-friendly file. Perfect for when you need to feed your codebase to Large Language Models (LLMs) or other AI tools like Claude, ChatGPT, DeepSeek, Perplexity, Gemini, Gemma, Llama, Grok, and more.
I used this for the first time to quickly bundle up a Python program into a single file that I could hand to Claude for help with a setup issue.
Assuming I'm already in the directory of the project, I can run:
$ npx repomix
I've been experimenting with mise lately for managing tool versions like node, so I'll use that.
Here I ask mise to run npx repomix in the context of Node.js v23:
$ mise exec node@23 -- npx repomix
It spit out a file called repomix-output.txt.
I wanted to drag that file from Finder into the Claude app, so I then ran:
$ open . -a Finder.app
Claude 3.7 Sonnet and Claude Code \ Anthropic
https://www.anthropic.com/news/claude-3-7-sonnetAn AI coding tool that I use directly from the terminal?! 👀
Claude Code is available as a limited research preview, and enables developers to delegate substantial engineering tasks to Claude directly from their terminal.
"thinking tokens"? Does that mean the input and output tokens that are used as part of intermediate, step-by-step "reasoning"?
In both standard and extended thinking modes, Claude 3.7 Sonnet has the same price as its predecessors: $3 per million input tokens and $15 per million output tokens—which includes thinking tokens.
The Claude Code Overview shows how to get started installing and using Claude Code in the terminal.
They all use it, by Thorsten Ball
https://registerspill.thorstenball.com/p/they-all-use-itMostly online, but in an occasional real-world conversation someone will be expressing their disinterest and dissatisfaction with LLMs in the realm of software development and they'll say, "I tried it and it just made stuff up. I don't trust it. It will take me less time to build it myself than fix all its mistakes."
My immediate follow-up question is usually "what model / LLM tool did you use and when?" because the answer is often GitHub copilot or some free-tier model from years ago.
But what I want to do is step back here like Thorsten and ask, "Aren't you curious? Don't you want to know how these tools fit into what we do and how they might start to reshape our work?"
What I don’t get it is how you can be a programmer in the year twenty twenty-four and not be the tiniest bit curious about a technology that’s said to be fundamentally changing how we’ll program in the future. Absolutely, yes, that claim sounds ridiculous — but don’t you want to see for yourself?
The job requires constant curiosity, relearning, trying new techniques, adjusting mental models, and so on.
What I’m saying is that ever since I got into programming I’ve assumed that one shared trait between programmers was curiosity, a willingness to learn, and that our maxim is that we can’t ever stop learning, because what we’re doing is constantly changing beneath our fingers and if we don’t pay attention it might slip aways from us, leaving us with knowledge that’s no longer useful.
I suspect much of the disinterest is a reaction to the (toxic) hype around all things AI. There is too much to learn and try for me to let the grifters dissuade me from the entire umbrella of AI and LLMs. I make an effort to try out models from all the major companies in the space, to see how they can integrate into the work I do, how things like Cursor can augment my day-to-day, discussing with others what workflows, techniques, prompts, strategies, etc. can lead to better, exciting, interesting, mind-blowing results.
I certainly don't think the writing is on the wall for all this GenAI stuff, but it feels oddly incurious if not negligent to simply write it off.
It’s none of their business
https://jose.omg.lol/posts/its-none-of-their-business/I like this framing. The code we usually start with when our software system is relatively simple probably has a pretty high degree of changeability. So, the work is to make sure we preserve so that it remains easy to change as the system grows in complexity.
To borrow from Sandi Metz's excellent book: "Design is the art of preserving changeability". My argument is that moving the logic into a domain object like Notification, which the Job simply calls, makes the code more changeable than dumping everything into the job itself.
An Analogy for Software Development
https://www.codesimplicity.com/post/an-analogy-for-software-development/Try this analogy the next time you’re trying to explain to someone who isn’t a software developer what it is that a software developer does.
I do want to think about how condense to the size of it down to an elevator pitch so that if it comes up in casual conversation, I can relate the idea quickly.
MarkDownload: browser extension to clip websites and download them into a readable markdown file
https://github.com/deathau/markdownloadI learned about this one from Taylor Bell. It's a browser (Chrome) extension that can grab the main content for a page as markdown which you can then download. The reason this is useful is because you can drag and drop a file like this into a tool like Claude, Cursor, ChatGPT, etc.
Let's say you are writing some code that uses a specific, niche library. Instead of relying on the LLM to know the ins and outs of the library and knowing about aspects of the latest version of that library, you can grab a markdown version of their latest docs and pass that in as context.
Based on the documentation and code examples in the given file, can you rework the previous script to make sure it is using the latest features and best practices of this library?
Or a similar thing I did recently was: after reading a blog post on a new-ish PostgreSQL feature, I grabbed the markdown for the blog post, and asked Claude for some examples of using the feature described in the blog post, but tailored to a situation I went on to describe.
When we can provide highly-specific, up-to-date context like this to an LLM, we are going to get much better results than if we toss up a one-sentence request.
I installed the extension directly from the Chrome Web Store, but I primarily linked to the GitHub project because that gives you the option to tweak and manually install the extension if that's preferred.
Validating Data Types from Semi-Structured Data Loads in Postgres with pg_input_is_valid
https://www.crunchydata.com/blog/validating-data-types-from-semi-structured-data-loads-in-postgres-with-pg_input_is_validThe pg_input_is_valid function is a handy way to check for whether rows of data conform to (are castable to) a specific data type. Let's say you have a ton of records with a payload text column. Those fields mostly represent valid JSON, but some are non-JSON error messages. You could write an update SQL statement like this:
UPDATE my_table
SET json_payload = CASE
WHEN pg_input_is_valid(payload, 'jsonb')
THEN payload::jsonb
ELSE '{}'::jsonb
END;
The post also shows off a nice technique for loading a ton of CSV data in where you may not be sure that every single row conforms to the various data types. It would be a shame to run a copy statement that loads 95% of the data and then suddenly fails and rolls back because of an errant field.
Instead, load everything in as text:
CREATE TEMP TABLE staging_customers (
customer_id TEXT,
name TEXT,
email TEXT,
age TEXT,
signup_date TEXT
);
-- copy in the data to the temp table
COPY staging_customers FROM '/path/to/customers.csv' CSV HEADER;
Then use an approach similar to what I described in the first code block to migrate the valid values over to other rows in the same or a different table.
In Elizabeth's example, the invalid records are ignored while the rest are moved to the new table:
INSERT INTO customers (name, email, age, signup_date)
SELECT name, email, age::integer, signup_date::date
FROM staging_customers
WHERE pg_input_is_valid(age, 'integer')
AND pg_input_is_valid(signup_date, 'date');
PostgreSQL Mistakes and How to Avoid Them
https://www.manning.com/books/postgresql-mistakes-and-how-to-avoid-themPostgreSQL Mistakes and How To Avoid Them reveals dozens of configuration and operational mistakes you’re likely to make with PostgreSQL. The book covers common problems across all key PostgreSQL areas, from data types, to features, security, and high availability. For each mistake you’ll find a real-world narrative that lays out context and recommendations for improvement.
I might have expected a book like this to be all about PostgreSQL-specific SQL and data modeling concepts. Even better, it also covers things like Performance, Administration features, Security, and High-Availability concepts.
Via LinkedIn
The Empty Promise of AI-Generated Creativity
https://hey.paris/posts/genai/This isn’t merely a technical limitation to be overcome with more data or better algorithms. It’s a fundamental issue: AI systems lack lived experience, cultural understanding, and authentic purpose—all essential elements of meaningful creative work. When humans craft stories, they draw upon personal struggles, cultural tensions, and genuine emotions. AI simply cannot access these wellsprings of authentic creation.
Avoid the nightmare bicycle
https://www.geoffreylitt.com/2025/03/03/the-nightmare-bicycleEmpower users to understand and use a product in whatever situation they might encounter.
Good designs expose systematic structure; they lean on their users’ ability to understand this structure and apply it to new situations. We were born for this.
Bad designs paper over the structure with superficial labels that hide the underlying system, inhibiting their users’ ability to actually build a clear model in their heads.
Alien’s ‘Standard Semiotic’, Pictograms and Icons
https://crewsproject.wordpress.com/2017/05/12/aliens-standard-semiotic-pictograms-and-icons/I just love the aesthetics of these pictographs and I love when movies go the extra mile on details like this.
Encountered this via this post.
AI haters build tarpits to trap and trick AI scrapers that ignore robots.txt
https://arstechnica.com/tech-policy/2025/01/ai-haters-build-tarpits-to-trap-and-trick-ai-scrapers-that-ignore-robots-txt/Fascinating!
Aaron clearly warns users that Nepenthes is aggressive malware. It's not to be deployed by site owners uncomfortable with trapping AI crawlers and sending them down an "infinite maze" of static files with no exit links, where they "get stuck" and "thrash around" for months, he tells users. Once trapped, the crawlers can be fed gibberish data, aka Markov babble, which is designed to poison AI models.
I imagine the basic idea is to have a page that a crawler would find if it ignored your robots.txt. It would be served with nonsense content and tons of internal dynamic links which go to more pages full of nonsense content and tons more internal dynamic links. Less of a maze and more of a never-ending tree.
But efforts to poison AI or waste AI resources don't just mess with the tech industry. Governments globally are seeking to leverage AI to solve societal problems, and attacks on AI's resilience seemingly threaten to disrupt that progress.
Weird to make this unqualified claim with no examples of how governments are trying to solve societal problems with AI -- I'm certainly having a hard time thinking of any.
Edit: Cloudflare has since launched something similar that it calls an AI Labyrinth.
When AI crawlers follow these links, they waste valuable computational resources processing irrelevant content rather than extracting your legitimate website data. This significantly reduces their ability to gather enough useful information to train their models effectively.
IAM Identity Center SSO credentials vs. IAM user access keys
https://www.reddit.com/r/aws/comments/1abszvz/comment/kjufbl4/I've been working with AWS and am noticing that the docs and AWS Console consistently recommend the use of short-term SSO-based credentials with IAM Identity Center user over long-term/permanent IAM user access keys.
I liked how the person in this reddit thread put it:
Typically, you would log in via your identity provider, which then generates short lived, role based credentials. This removes the need for IAM user access keys living permanently on your workstation.
Another person posts this comprehensive set of steps which closely mirrors what I had to do setting up IAM Identity Center access for a project:
Quick start:
1. Enable Organizations (even if you have 1 personal account)
2. Enable IAM Identity Center (its own service, confusingly not part of IAM). Note the URL listed under "AWS access portal URL", you'll need that in a minute.
3. Create a User for yourself in IAM Identity Center (this is different than IAM users)
4. Go back to Organizations. Select Accounts, your account, and add your new user to the account with the permissions you want.
5. Get a cup of coffee, AWS takes a hot minute to sync up what you just did.
6. Browse to the Start URL you copied in step 2. Make sure you can log in and that you see the Account and the Role you setup in step 4. While you're logged in, do yourself a favor and add MFA to your new user.
7. Go to your terminal and type: aws configure sso You'll be asked to name the SSO session name, call it whatever you'd like. Next it wants the "Start URL", this is the URL from step 2 above.
8. Point your profile at it: export AWS_PROFILE=my-new-sso-profile
9. Finally we get to actually log in: aws sso login This will open a browser window and log you in through the Console. Once complete your aws cli will be logged in with a temporary, role based session, no long lived credentials on your machine at all.It's a long road to get here, but once you've got this setup it's a breeze to start your day with "aws sso login" and you've setup your account in a proper way that gives you a lot more options going forward. It's certainly more work than signing up for a TikTok account, but this is also a much more serious, professional product.
My LLM codegen workflow atm
https://harper.blog/2025/02/16/my-llm-codegen-workflow-atm/Flip the script by getting the Conversational LLM to ask you questions instead of you asking it questions.
Ask me one question at a time so we can develop a thorough, step-by-step
spec for this idea. Each question should build on my previous answers, and
our end goal is to have a detailed specification I can hand off to a
developer. Let’s do this iteratively and dig into every relevant detail.
Remember, only one question at a time.Here’s the idea:
...
This is a good way to hone an idea, rubberduck, and think through a problem space.
I tried a session of this with Claude Sonnet 3.7. It asked a lot of good questions and got me thinking. After maybe 8 or so questions I ran into the warning from Claude about the conversation getting too long and running into usage limits (not sure what to do about that speed bump yet).
Artichoke Hold Cocktail Recipe 🍹
https://www.diffordsguide.com/cocktails/recipe/6586/artichoke-holdI was at Warehouse Liquors in downtown Chicago a couple months ago. Talking to one of the employees about Cynar, they mentioned they used to bartend and one of their favorite things to make with it is a drink called Artichoke Hold.
They gave me the following recipe which varies a little from the Diffords one.
- 5 drops saline
- 0.5oz orgeat
- 0.75oz Lime juice (not lemon like diffords)
- 0.5oz Elderflower liqueur
- 0.75oz Cynar
- 0.75oz Smith & Cross (one of my favorite rums)
Shake with ice, pour over fresh pebble ice in a Mai Tai glass, garnish with a mint sprig.
The 10 Rules of Vibe Coding, quoting John Lindquist
https://x.com/johnlindquist/status/1894772728588284306
- Always start with deep research
- Always create a plan from the research
- Break the plan down into small, testable tasks
- AI Agents tackle one task at a time
- Agents must be able to verify their work
- Agents need context of the full project (file-tree, goals, etc), even for small tasks
- git is your friend
- Capture everything at the EOD, then deep research how to do better tomorrow
- When agents fail, go AFK and clear your head. Brute force never works and burns money.
- Dictate anything longer than a sentence
“git is your friend” resonates with me for any AI (or non-AI) coding because you can quickly overwrite a bunch of in-progress changes. Small, incremental diffs are the way.
What is vibe coding?
It may have been originally coined in this tweet by Andrej Karpathy:
There's a new kind of coding I call "vibe coding", where you fully give in to the vibes, embrace exponentials, and forget that the code even exists. It's possible because the LLMs (e.g. Cursor Composer w Sonnet) are getting too good. Also I just talk to Composer with SuperWhisper so I barely even touch the keyboard. I ask for the dumbest things like "decrease the padding on the sidebar by half" because I'm too lazy to find it. I "Accept All" always, I don't read the diffs anymore. When I get error messages I just copy paste them in with no comment, usually that fixes it. The code grows beyond my usual comprehension, I'd have to really read through it for a while. Sometimes the LLMs can't fix a bug so I just work around it or ask for random changes until it goes away. It's not too bad for throwaway weekend projects, but still quite amusing. I'm building a project or webapp, but it's not really coding - I just see stuff, say stuff, run stuff, and copy paste stuff, and it mostly works.
"And it mostly works." 🥴
Build Your Own Database From Scratch in Go
https://build-your-own.org/database/Someone shared their Go-based database implementation on Reddit and mentioned that they used this book as a guide.
Understand databases from the bottom up by building your own, in small steps, and with simple Golang code.
- Start with a B+tree, the data structure for querying and manipulating the data.
- Make it durable, that’s what makes a DB different from a file.
- Relational DB with concurrent transactions on top of the copy-on-write B+tree KV.
- A SQL-like query language, the finishing touch.
What My Morning Journal Looks Like
https://tim.blog/2015/01/15/morning-pages/I was grabbing coffee with someone the other day. I mentioned that I sometimes go the whole day feeling like I have dozens of scattered things I need to get to and that it destroys my focus and sense of calm. They recommended starting the day with morning pages.
Morning pages don’t need to solve your problems. They simply need to get them out of your head, where they’ll otherwise bounce around all day like a bullet ricocheting inside your skull.
Comparison of the transaction systems of Oracle and PostgreSQL
https://www.cybertec-postgresql.com/en/comparison-of-the-transaction-systems-of-oracle-and-postgresql/Nice example of when deferrable constraints matter in PostgreSQL.
CREATE TABLE tab (id numeric PRIMARY KEY);
INSERT INTO tab (id) VALUES (1);
INSERT INTO tab (id) VALUES (2);
UPDATE tab SET id = id + 1;
ERROR: duplicate key value violates unique constraint "tab_pkey"
DETAIL: Key (id)=(2) already exists.
The reason is that PostgreSQL (in violation of the SQL standard) checks the constraint after each row, while Oracle checks it at the end of the statement. To make PostgreSQL behave the same as Oracle, create the constraint as DEFERRABLE. Then PostgreSQL will check it at the end of the statement.
Dr. Dave's Runout Drill System 🎱
https://drdavepoolinfo.com//bd_articles/2020/oct20.pdfThis is a level-based system from Novice to Pro that allows you to evaluate where you are currently at in your ability to run out a table. You can use it to check your ability now and then later to measure progress over time.
The Go Gopher
https://go.dev/blog/gopherThis article shares some of the history of how the Go gopher came about. It was designed by Renee French, originally for a radio station promotion in ~1999, and then adapted for Go in ~2009.
I also found a gopher drawing on French's blogspot from 2011 -- https://reneefrench.blogspot.com/2011/07/blog-post_31.html
Calling private methods without losing sleep at night
https://justin.searls.co/posts/calling-private-methods-without-losing-sleep-at-night/A little thing I tend to do whenever I make a dangerous assumption is to find a way to pull forward the risk of that assumption being violated as early as possible.
Tests are one way we do this, but tests aren’t well-suited to all the kinds of assumptions we make about our software systems.
We assume our software doesn’t have critical vulnerabilities, but we have a pre-deploy CI check (via brakeman) that alerts us when that assumption is violated and CVEs do exist.
Or as Justin describes in this post, we can have some invariants in our Rails initializer code to draw our attention to other kinds of assumptions.
From web developer to database developer in 10 years
http://notes.eatonphil.com/2025-02-15-from-web-developer-to-database-developer-in-10-years.htmlA one-year retrospective of Phil Eaton’s time at EnterpriseDB and the way he made his own path into database development to get there.
Advice for newsletter-ers
https://www.robinsloan.com/notes/newsletter-seasons/A personal email newsletter ought to be divided into seasons, just like a TV show.
The benefits being:
- a sense of progress: of going and getting somewhere.
- an opportunity for breaks: to pause and reflect, reconfigure.
- an opportunity, furthermore, to make big changes: in terms of subject, structure, style.
- an opportunity to stop: gracefully.
I like this as a way of setting expectations for yourself and your audience. I think it also opens up an opportunity to be playful and experiment. Having a finish line rather than a vanishing point on the horizon is energizing.
I see podcasts that go both directions on this. Some podcasters start recording with no timeline parameters in mind. Others approach it with a definite set of episodes they want to do. I'd never thought about translating that to a newsletter.
Shared by Matt Webb.
Git - Plumbing and Porcelain
https://git-scm.com/book/en/v2/Git-Internals-Plumbing-and-PorcelainI like this concept of Plumbing versus Porcelain CLI commands. I recently referenced it in Connect To Production Rails Console on AWS / Flightcontrol - Notes from VisualMode.
because Git was initially a toolkit for a version control system rather than a full user-friendly VCS, it has a number of subcommands that do low-level work and were designed to be chained together UNIX-style or called from scripts. These commands are generally referred to as Git’s “plumbing” commands, while the more user-friendly commands are called “porcelain” commands.
Reflections on 25 years of Interconnected
https://interconnected.org/home/2025/02/19/reflectionsjust an incredible quote from someone who has now been blogging for 25 years
I felt when I started in February 2000 that I was coming to blogging late. I procrastinated about setting it up. People I knew were already doing it.
And so much more interesting reflection and history of the emergence of blogging.
Everything starts with awareness. So be noisy about the precise things that I’m interested in, and see what happens. That means product design but also means nonsense about weird history or whatever.
End of the road for PostgreSQL streaming replication?
https://www.cybertec-postgresql.com/en/end-of-the-road-for-postgresql-streaming-replication/These kinds of performance / stress tests of PostgreSQL are always fascinating to me. There are many factors you need to consider about the machine’s stats, you have to set up multiple databases, maybe multiple clusters, and then after running a tool like pgbench, you have to make sure you’ve observed and captured useful data that you can draw conclusions from.
To try to quantify the crossover point, I ran a small test. I initialized a 8GB pgbench database that fits into shared buffers, then I set up WAL archiving and took a backup. Next, I ran 30min of pgbench with synchronous_commit=off to generate some WAL. On a 24 thread workstation, this generated 70GB of WAL containing 66M pgbench transactions, with an average speed of 36.6k tps. Finally, I configured Postgres to run recovery on the backup. This recovery was able to complete in 372 seconds, or 177k tps.
Here are some notes from AWS on benchmarking Postgres with pgbench: https://docs.aws.amazon.com/whitepapers/latest/optimizing-postgresql-on-ec2-using-ebs/postgresql-benchmark-observations-and-considerations.html
Learn Postgres at the Playground
https://www.crunchydata.com/blog/learn-postgres-at-the-playgroundThe folks at CrunchyData created a playground for playing around with and learning PostgreSQL... right in the browser.
SQL Tricks for More Effective CRUD is one of dozens of the tutorials they have since published.
This is made possible via WASM. Crazy Idea to Postgres in the Browser goes into more details about how they pulled it off.
It seems like there is a lot of energy moving in this direction. When I search "postgres wasm", several of the results are about PGlite from ElectricSQL (which is building a sync engine, a play in the local-first space).
supabase released what they are calling database.build that connects you to a Postgres database in the browser and gives you AI tools for interacting with that database.
the in-browser Postgres sandbox with AI assistance. With database.build, you can instantly spin up an unlimited number of Postgres databases that run directly in your browser (and soon, deploy them to S3). Each database is paired with a large language model (LLM)...
The secret to perfectly calculate Rails database connection pool size
https://island94.org/2024/09/secret-to-rails-database-connection-pool-sizetl;dr: don't compute the pool size, set it to a big number, the pool size is the max that Rails enforces, but the thing that matters is the number of connections available at the database (which is a separate issue).
If, rather, you're running out of connections at the database, then try things like:
- reduce the number of Puma threads
- reduce background job threads (e.g. via GoodJob, Solid Queue, etc.)
- "Configure anything else using a background thread making database queries"
- among others
Or increase the number of connections available at the database with a tool like PgBouncer.
This post was written by the person who created GoodJob.
Solving Logic Puzzles with Microsoft's z3 SAT Soler
https://www.wdj-consulting.com/blog/logicpuzzle-z3/This post walks through how to formulate a logic puzzle as the declarative elements that a SAT solver like z3 knows how to take in. It can then determine if the given elements are satisfiable (SAT) or not (UNSAT). It can also produce the set of values that make it SAT which is then a solution to the puzzle.
Here is the GitHub project for z3: https://github.com/Z3Prover/z3
Erich's Puzzle Palace
https://erich-friedman.github.io/puzzle/index.htmlThis is the kind of site that the internet was created for. A little HTML, a little CSS, a repeating puzzle piece background. Beautiful.
Here is another cool puzzle site that I found linked from the Interactive links: https://pedros.works/kudamono/pages/full-house.html
Target Pool Drills 🎱
https://billiards.colostate.edu/faq/drill/target/A couple different methods, drills, and tools for working on sinking a ball and moving the cue to a specific target on the table.
Here is what on redditor suggests as a better alternative to Target Pool.
Skyscrapers Puzzle
https://www.conceptispuzzles.com/index.aspx?uri=puzzle/skyscrapers/rulesI was browsing through this list of puzzles for one that caught my eye. Skyscrapers jumped out and I was curious how to play.
Based on the size of the grid, let's say it is 5, the rules are:
- every row needs to contain the numbers 1 through 5
- every column needs to contain the numbers 1 through 5
- thinking of the numbers in the grid as building heights, the arrowed-numbers indicate exactly how many buildings are in your sightline for that row or column. If the first number is a 5, then the sightline is 1. If there is a sequence of 3 | 2 | 4 | 5 | 1, then the sightline is 3 because you can see 3, then 4, and then 5, while the 2 is obscured by 3, and the 1 is obscured by everything. Viewed from the other side, the sightline is 2 because you can see 1, then 5, and then nothing else.
A starting puzzle looks like this:
2 1
↓ ↓
+–––+–––+–––+–––+–––+
4→ | | | | | |
+–––+–––+–––+–––+–––+
4→ | | | | | |
+–––+–––+–––+–––+–––+
| | | | | | ←5
+–––+–––+–––+–––+–––+
| | | | | |
+–––+–––+–––+–––+–––+
| | | | | |
+–––+–––+–––+–––+–––+
↑ ↑
2 1
And the solution to that one looks like this:
2 1
↓ ↓
+–––+–––+–––+–––+–––+
4→ | 1 | 2 | 4 | 5 | 3 |
+–––+–––+–––+–––+–––+
4→ | 2 | 3 | 1 | 4 | 5 |
+–––+–––+–––+–––+–––+
| 5 | 4 | 3 | 2 | 1 | ←5
+–––+–––+–––+–––+–––+
| 3 | 5 | 2 | 1 | 4 |
+–––+–––+–––+–––+–––+
| 4 | 1 | 5 | 3 | 2 |
+–––+–––+–––+–––+–––+
↑ ↑
2 1
Other places to find these puzzles:
TIOBE Index - Popularity Index for Programming Languages
https://www.tiobe.com/tiobe-index/This index was completely new to me. I was interested to see Python, C++, and Java in the top three spots; SQL and Go holding strong at 7 and 8 respectively; Ruby at the 19th spot; Prolog, of all things, in the 20th spot; and lastly, the omission of TypeScript.
Heard about this via Nate Berkopec.
Modern Front-End Development for Rails, Second Edition: Hotwire, Stimulus, Turbo, and React by Noel Rappin
https://pragprog.com/titles/nrclient2/modern-front-end-development-for-rails-second-edition/I learned about this book via this post from rosa.codes.
In the replies to that post are several other resources recommend by the community:
- The Rails and Hotwire Codex: Build an app for web, iOS, and Android
- Hotrails - Learn modern Ruby on Rails with Hotwire
- Master Hotwire: Master Hotwire to Build Modern Web Apps with Rails Simplicity
puzz.link puzzle index
https://puzz.link/db/I was trying to track down a generalized name for the type of puzzle that LinkedIn's Queens puzzle falls into and I came across a reddit post that linked to this growing database of contributor-submitted puzzles.
I guess it is a variation of the Eight Queens Puzzle.
Here are the names of all the puzzles that you can search by in the database:
- aho
- akari
- akichi
- amibo
- angleloop
- anglers
- antmill
- aqre
- aquapelago
- aquarium
- araf
- armyants
- arukone
- ayeheya
- balance
- barns
- battleship
- bdblock
- bdwalk
- bonsan
- bosanowa
- box
- brownies
- canal
- castle
- cave
- cbanana
- cbblock
- chainedb
- chocona
- circlesquare
- cocktail
- coffeemilk
- cojun
- compass
- context
- coral
- country
- creek
- crossstitch
- cts
- curvedata
- dbchoco
- detour
- disloop
- dominion
- doppelblock
- dosufuwa
- dotchi
- doubleback
- easyasabc
- evolmino
- factors
- familyphoto
- fillmat
- fillomino
- firefly
- firewalk
- fivecells
- fourcells
- fracdiv
- geradeweg
- goishi
- gokigen
- guidearrow
- haisu
- hakoiri
- hanare
- hashi
- hebi
- herugolf
- heteromino
- heyablock
- heyabon
- heyawake
- hinge
- hitori
- icebarn
- icelom
- icelom2
- icewalk
- ichimaga
- ichimagam
- ichimagax
- interbd
- juosan
- kaero
- kaidan
- kaisu
- kakuro
- kakuru
- kazunori
- kinkonkan
- koburin
- kouchoku
- kramma
- kramman
- kropki
- kurochute
- kuroclone
- kurodoko
- kuromenbun
- kurotto
- kusabi
- ladders
- lapaz
- lightshadow
- lither
- lits
- lohkous
- lollipops
- lookair
- loopsp
- loute
- magnets
- makaro
- martini
- masyu
- maxi
- meander
- mejilink
- midloop
- minarism
- mines
- mintonette
- mirrorbk
- mochikoro
- mochinyoro
- moonsun
- mukkonn
- myopia
- nagare
- nagenawa
- nanameguri
- nanro
- nawabari
- news
- nikoji
- nondango
- nonogram
- norinori
- norinuri
- nothing
- nothree
- numlin
- numrope
- nuribou
- nurikabe
- nurimaze
- nurimisaki
- nuriuzu
- oneroom
- onsen
- ovotovata
- oyakodori
- paintarea
- parquet
- patchwork
- pencils
- pentatouch
- pentominous
- pentopia
- pipelink
- pipelinkr
- putteria
- ququ
- railpool
- rassi
- rectslider
- reflect
- remlen
- renban
- ringring
- ripple
- roma
- roundtrip
- sananko
- sashigane
- sashikazune
- sato
- scrin
- shakashaka
- shikaku
- shimaguni
- shugaku
- shwolf
- simplegako
- simpleloop
- skyscrapers (rules)
- slalom
- slashpack
- slitherlink
- snake
- snakeegg
- snakepit
- squarejam
- starbattle
- statuepark
- stostone
- sudoku
- sukoro
- sukororoom
- swslither
- symmarea
- tajmahal
- takoyaki
- tapa
- tapaloop
- tasquare
- tatamibari
- tateyoko
- tawa
- tentaisho
- tents
- teri
- tetrochain
- tetrominous
- tilepaint
- toichika
- toichika2
- tontonbeya
- tontti
- trainstations
- tren
- triplace
- tslither
- turnaround
- uramashu
- usoone
- usotatami
- view
- voxas
- vslither
- wafusuma
- wagiri
- walllogic
- waterwalk
- wblink
- wittgen
- yajikazu
- yajilin
- yajilin-regions
- yajisoko
- yajitatami
- yinyang
- yosenabe
New microblog with TILs
https://jvns.ca/blog/2024/11/09/new-microblog/There is something really cool about seeing other people adopt a practice of writing TIL-style posts and coming to the same realizations and conclusions that I did with mine.
TILs are great learning resources and reference resources:
I think this new section of the blog might be more for myself than anything, now when I forget the link to Cryptographic Right Answers I can hopefully look it up on the TIL page.
In Simon Willison's 1 Year TIL Retrospective, he points to how they reframe writing and publishing something:
The thing I like most about TILs is that they drop the barrier to publishing something online to almost nothing... The bar for a TIL is literally “did I just learn something?”—they effectively act as a public notebook.
and on the value of always having a learning mindset:
They also reflect my values as a software engineer. The thing I love most about this career is that the opportunities to learn new things never reduce—there will always be new sub-disciplines to explore, and I aspire to learn something new every single working day.
It was fun to read through both of these posts having just myself reflected on A Decade of TILs.
CONVENTIONS.md file for AI Rails 8 development
https://gist.github.com/peterc/214aab5c6d783563acbc2a9425e5e866Peter Cooper put together this file of conventions that a tool like Cursor or Aider should follow when doing Rails 8 development.
One issue that I constantly run into with Cursor is that it creates a migration file that is literally named something like db/migrate/[timestamp]_add_users_table.rb, instead of suggesting/running the migration generator command provided by Rails. I'm curious if there is a way to effectively get these tools to follow that workflow -- generate the file with rails g ... and then inject that file with the migration code.
Use Rails' built-in generators for models, controllers, and migrations to enforce Rails standards.
Maybe that rule is enough to convince Cursor to use the generator.
The Best Self-Hosted RSS Feed Readers
https://lukesingham.com/rss-feed-reader/I'm trying to avoid going down a self-hosted RSS feed reader rabbit hole, but still interesting to browse through this and see what the options are.
The winner was miniflux which appears to still be actively maintained.
The author linked at the bottom to Archive Box which is a self-hosted tool for archiving web pages, videos, etc. to avoid link rot for things that you want to always be able to access.
See also Best free RSS reader apps for Mac.
Where the Rails Devs Are
https://bsky.app/starter-pack/did:plc:qkn6arplsv2pmw2zredwzqkm/3kw3olx5gf72mSome lists and communities where you can find Ruby on Rails developers and what they are posting:
- Ruby on Rails Bluesky Starter Pack
- Ruby on Rails Community on Twitter
- Rails Subreddit
- Ruby on Rails group on LinkedIn
- GoRails Discord
See also Free Ruby on Rails Communities.
Build complex CLIs with type safety and no dependencies
https://bloomberg.github.io/stricli/I heard about this from Matt Pocock who says he is moving a tool he is building from Commander to StriCli.
CrossPoster from LlamaIndex
https://bsky.app/profile/llamaindex.bsky.social/post/3lhtokiscv22xI generally prefer the effort and authenticity of manually tailoring each cross-post to the social network it is going to. However, some things can easily be shared in the same way/format across Bluesky, Twitter, and Linkedin. For those, try using CrossPoster.
From hours to 360ms: over-engineering a puzzle solution
https://blog.danielh.cc/blog/puzzleI thought this was going to be a sudoku thing at first, but it appears to be a problem with a bigger problem space that you have solve exhaustively because you need to find every solution in order to guarantee that you've found the largest GCD.
The code/solutions presented by the author are in Rust.
The Brutal Drill 🎱
https://www.reddit.com/r/billiards/comments/1ij3no5/comment/mbbnjeb/a good drill for practicing frozen on the rails shots and good position / speed control
Five coding hats
https://dubroy.com/blog/five-coding-hats/It doesn't make sense to write code with the exact same approach regardless of the circumstances. Depending on the situation, it may be more appropriate to take a more fast and loose approach than a careful and rigorous one.
Scrappy and MacGyver Hats vs. Captains Hat
a real-world illustration of this that jumps to mind is "setting up payment processing for my app"
common approach: fully wire up stripe webhooks with your backend logic and database, etc.
scrappy approach: stripe payment alerts me, I go into Rails console and add user record for their email
Mistakes are part of the process
https://bsky.app/profile/pketh.org/post/3lhgqaedgyb2tNo one wants to make ‘ugly’ art, or write a ‘bad’ document. But struggling and making mistakes is an important part of developing skills and – increasingly important – finding your own voice.
Postfix Setup for Action Mailbox
https://stackoverflow.com/a/61629911/535590This stackoverflow answer provides a ton of good detail how on to get Postfix setup with Rails' Action Mailbox.
I also wanted to document the steps I took with the added detail that this is for a Hatchbox and Hetzner configuration:
Find the email that Hatchbox sent ([Hatchbox] Your new server password) with the password for the
deployuser to be able to run commands asrootwithsudo. This is needed for a couple things.Hatchbox / Hetzner do not have
postfixinstalled, so it needs to be done manually.$ sudo apt-get update $ sudo apt-get install postfixCreate the virtual mailbox mapping file which tells Postfix what our catch-all email recipient will be —
sudo vi /etc/postfix/virtual.mydomain.tld anything @mydomain.tld catch-all@mydomain.tldThe first line tells Postfix that we accept email for our domain. The second line is the catch-all line which takes any mail that doesn't match a specific address and sends it to
catch-all@mydomain.tldassuming thecatch-alluser exists.Create the
catch-alluser.$ sudo useradd --create-home --shell /sbin/nologin catch-allAdd Postfix transport file which indicates the name of the thing that is going to forward emails to Rails —
sudo vi /etc/postfix/transport:mydomain.tld forward_to_rails:Compile
virtualandtransportinto Berkley DB files withpostmap. This can be done from whatever directory you're already in.$ sudo postmap /etc/postfix/virtual $ sudo postmap /etc/postfix/transportNotice in
ls /etc/postfixthat there is now avirtual.dbandtransport.dbfile.Add this email forwarding script (with the command mentioned in the Rails Action Mailbox docs for Postfix) to
/usr/local/binin a file likeemail_forwarder.sh:#!/bin/sh cd /home/deploy/visualmode-dev-rails-app/current && bin/rails action_mailbox:ingress:postfix URL='https://mydomain.tld/rails/action_mailbox/relay/inbound_emails' INGRESS_PASSWORD='ingress_password'Note that this command needs a
URLwhich is your fully-qualified URL followed by/rails/action_mailbox/relay/inbound_emails. It also needs theINGRESS_PASSWORDthat Rails will be configured with, such as with theRAILS_INBOUND_EMAIL_PASSWORDenv var.Then at the end of the
master.cffile, I added the following lines, ensuring not to modify anything else in there —sudo vi /etc/postfix/master.cf:forward_to_rails unix - n n - - pipe flags=Xhq user=deploy:deploy argv=/usr/local/bin/email_forwarder.sh ${nexthop} ${user}Since my user is already called
deploy, I can leave theuser=deploy:deployas is.Update the
main.cffile with mapping and transport files —sudo vi /etc/postfix/main.cf:transport_maps = hash:/etc/postfix/transport virtual_alias_maps = hash:/etc/postfix/virtualThen to make sure that Postfix is aware of all the latest changes, I reload it.
$ sudo postfix reload $ sudo systemctl reload postfix
UltraHook - Receive webhooks on localhost
https://www.ultrahook.com/UltraHook makes it super easy to connect public webhook endpoints with development environments.
Free tool and Ruby gem for testing webhooks in local development by exposing your app to the public web.
Reminds me of webhook.site another tool for this kind of local dev testing.
Ultrahook was recommended as part of this Postmark tutorial on setting up inbound email handling in Rails.
From pain to productivity: How I learned to code with my voice
https://whitep4nth3r.com/blog/how-i-learned-to-code-with-my-voice/Primary tools used:
- Talon
- Cursorless
- Apple Voice Control
- Rango
The Attention Trap
https://www.commonwealmagazine.org/attention-trapattention has of course always mattered... But it is because we have today found a way of treating something fundamentally intangible—the stream of consciousness—as fungible into other kinds of goods (like money or data) that it has become an object charged with public concern.
smartphone :: rosary
One might say that the monastery was the first attention platform, the first setting in which attention and its disciplines were a central and explicit issue—and not only in the day’s large blocks of activity, but in the cracks and breaks between them as well. For this reason, the philosopher Byung-Chul Han has compared the smartphone to the rosary.
Increase profits by finding the most inviting hue of blue
Google (to take one well-known example) claims to have made an additional $200 million dollars in 2014 solely by having tuned its advertising links to precisely the right shade of blue.
Severance vibes
Our fragmented sensory experience during these packets of time is reified into data. Meanwhile, our experience of time is severed from the past and future and exiled into a kind of eternal present.
This is how I run. I don't listen to music or audiobooks. I don't hit the pavement with specific things to think through. I just run and my mind (and attention) ebbs and flows to the rhythm of my route and my mind.
Instead, we might try to reconceive attention not as a moment or as a product of a momentary decision but as a rhythm inhering within a pattern of life.
Article shared by David Crespo.
Pika – Perfect Code Screenshots
https://pika.style/templates/code-imageThere are a number of tools out there for pasting in a snippet of code to get a nice looking screenshot for social media posts. This one is the tool I currently prefer.
I used to use carbon quite a bit in the past, but the last number of times I used it, the interface was janky.
Brag Book with Automation
https://bsky.app/profile/minamarkh.am/post/3lhbzikqkj22eTaylor posted a great reminder about maintaining a brag book:
Yearly reminder to create your Brag Book to increase your chances of getting promoted, having more meaningful review cycles, or just lifting your spirits any time you feel "I haven't done anything!".
When you have an impactful win, add it to your Brag Book.
And then Mina shared the idea of setting up an automation in something like Slack as a low-friction way of aggregating these kinds of wins and affirmations in one place.
The BLACKHOLE Storage Engine :: MySQL
https://dev.mysql.com/doc/refman/8.4/en/blackhole-storage-engine.htmlReading through the ActiveRecord Migrations docs I came across an example demonstrating how to specify database-specific options like ENGINE=BLACKHOLE.
What is ENGINE+BLACKHOLE I wondered.
The BLACKHOLE storage engine acts as a “black hole” that accepts data but throws it away and does not store it. Retrievals always return an empty result
The provide the following code block to demonstrate the above:
mysql> CREATE TABLE test(i INT, c CHAR(10)) ENGINE = BLACKHOLE;
Query OK, 0 rows affected (0.03 sec)
mysql> INSERT INTO test VALUES(1,'record one'),(2,'record two');
Query OK, 2 rows affected (0.00 sec)
Records: 2 Duplicates: 0 Warnings: 0
mysql> SELECT * FROM test;
Empty set (0.00 sec)
Reading further into the MySQL docs on this, there are all kinds of interesting behaviors and use cases:
Suppose that your application requires replica-side filtering rules, but transferring all binary log data to the replica first results in too much traffic. In such a case, it is possible to set up on the replication source server a “dummy” replica process whose default storage engine is BLACKHOLE
Data migrations with the `maintenance_tasks` gem
https://railsatscale.com/2023-01-04-how-we-scaled-maintenance-tasks-to-shopify-s-core-monolith/article.htmlThe maintenance_tasks gem from Shopify is a mountable Rails engine for running one-off data migrations from a UI that is separate from the schema migration lifecycle.
In the past, I've used the after_party gem for this use case. That gem runs data migrations tasks typically as part of a post-deploy process with the same up/down distinction as schema migrations.
It seems the big difference with maintenance_tasks is that they are managed from a UI and that there are many more features, such as batch, pausing, rerunning, etc. You can observe the progress of these tasks from the UI as well.
There is a Go Rails Episode about how to use the maintenance_tasks gem.
DigitalOcean Spaces | S3-Compatible Object Storage
https://www.digitalocean.com/products/spacesDigitalOcean has S3-compatible object storage that is super affordable with transparent pricing.
$5 per month for:
- 250 GiB storage
- 1 TiB outbound transfer
- $0.02/GiB additional storage
- $0.01/GiB additional transfer
Is it worth writing about? | notes.eatonphil.com
https://notes.eatonphil.com/is-it-worth-writing-about.htmlThis article and the following quote came up in Chapter 1 of Writing for Developers.
Even if you're writing about a popular topic, there's still a chance your post gets through to someone in a way other posts do not.
Why write? To practice writing so that you can write better in all sorts of venues and formats. To cement understanding because putting it in words makes you go a step deeper and wrestle with the hazy parts. To provide your perspective in case that is more accessible to someone than whatever else is out there. To demonstrate your expertise.
I usually try to wrap my head around the aspects I don’t understand before hitting publish. But for when I don’t have time to do that, I can call out that it is a gap in understanding.
Write to explain and teach. When you don't understand something, call out that you don't understand it. That's not a bad thing, and the internet is normally happy to help.
The Slotted Counter Pattern — PlanetScale
https://planetscale.com/blog/the-slotted-counter-patternTo avoid contention on a single high-write counter column, you can create a generic slotted counter table with polymorphic associations to anything that needs counting. Then to update the count, you increment the count in one of one hundred random slots. You can either sum the counts for a specific record and type to get the count, or you can have a process to roll up the count periodically and store it nearer to the original record.
I wonder what heuristics you could use to scale the number of slots you use for a given entity. That way for a relatively low-update entity, you spread the counts over, say, 3 counter slots. And with a very high-update entity, you spread it across, say, 50 or 100 slots.
Useful label-based GitHub Actions workflows
https://www.jessesquires.com/blog/2021/08/24/useful-label-based-github-actions-workflows/#updated-21-march-2022I was looking at how others have implemented a GitHub Action to trigger a failed check on a PR when it is tagged with certain labels, such as No Merge or WIP.
I came across this blog post which included an updated code block on how to achieve this without any 3rd-party actions. This is also the simplest example I found coming in at 18 lines.
My contribution was to alter the if check to look at multiple labels:
jobs:
do-not-merge:
if: ${{ contains(github.event.*.labels.*.name, 'no merge') || contains(github.event.*.labels.*.name, 'wip') }}
I also printed out the labels to add a bit more detail in the action log:
steps:
- name: Check for label
run: |
echo "Pull request label prevents merging"
echo "Labels: ${{ join(github.event.*.labels.*.name, ', ') }}"
echo "This workflow fails so that the pull request cannot be merged"
exit 1
TIL'd: Use Labels To Block PR Merge
Tor Lowry's Stroke Drill 🎱
https://www.reddit.com/r/billiards/comments/1ie3j1h/comment/ma4icr3/Tor Lowry’s stroke drill is to stop playing pool. No shooting balls or playing games until you finish the drill. It may take a week.
The idea being that you need to force yourself to completely overhaul your stroke by fully focussing on consistency that gets baked into your muscle memory.
You [put] a ball on the headstring at the top of the table. And you shoot it like a direct scratch straight into a corner pocket on the other side of the table. You do that 1,000+ times. You can use object balls as cueballs for this and go through 16 at a time. But the important thing is that each one is treated like a real shot in terms of fundamentals.
Nothing fancy. 1000+ center ball shots right into the heart of the pocket. Nothing else to distract your focus from applying all the fundamentals to each of those 1000+ shots.
Set up the ball. Stand behind the shot (scratch direct to the pocket). Plant your back foot on the shooting line. Step your front foot forward as you get down and place your stick on the shooting line. Dress the tip up to the cueball for a center ball strike. Couple practice strokes. Pause. Few more micro strokes within an inch of the call. Pause. Easy pull back. Smooth transition. Controlled and assertive delivery. And you must follow through at least 6” past the cueball resting the tip on the table at the finish. That last sentence is the most important. Put a sticker on the table of where the tip must finish if you need to.
This is why we're just hitting scratch shots. There are a dozen aspects of the pre-shot and shot routine that we instead need to be focused on.
It does not feel intuitive to me that a center-ball shot is going to result in follow-through that leaves the cue tip resting on the table. That feels like a big adjustment. It probably helps to cement a full, smooth follow-through.
Here’s what you’re doing. You’re committing good fundamentals to muscle memory. And you’re doing it through repetition. And you can’t skip it. You can’t say you’re already good on it. You can’t know this, you have to earn it. Just like my stroke is garbage left handed. I can’t “know” my stroke to be better left handed. It takes repetition just like a pianist practicing scales slowly so that later on they can play fast and intuitively. You need to grind at repetition to make the mind-body connection of intention to brain to nerves to muscles to be well worn in to muscle memory that you can’t do it wrong.
Repetition of intentional, deliberate practice to unlearn bad practices and solidify good ones. This way you can eventually shoot well with muscle memory rather than thinking through every granular piece of a good stroke.
Creating and using events - Fathom Analytics
https://usefathom.com/docs/events/overviewFathom has an SDK for tracking various events such as link clicks, newsletter signups, and page loads. This will be displayed in the dashboard as event completions.
Smidgeons Stream | Maggie Appleton
https://maggieappleton.com/smidgeonsI'm intrigued by this form of micro-content that Maggie Appleton is calling a Smidgeon. It is similar to Simon Willison's blogmark concept. The notable difference to me is that they aren't explicitly tied to some external URL.
With a blogmark, I'm linking to some blog, resource, whatever on the internet and tying some of my own commentary to it. Whereas with a smidgeon, I don't necessarily need to lead with a URL. One might just be a small bit of freeform thought.
Built-in Rails Database Rake Tasks
https://github.com/rails/rails/blob/1dd82aba340e8a86799bd97fe5ff2644c6972f9f/activerecord/lib/active_record/railties/databases.rakeIt's cool to read through the internals of different rake tasks that are available for interacting with a Rails database and database migrations.
For instance, you can see how db:migrate works:
desc "Migrate the database (options: VERSION=x, VERBOSE=false, SCOPE=blog)."
task migrate: :load_config do
ActiveRecord::Tasks::DatabaseTasks.migrate_all
db_namespace["_dump"].invoke
end
First, it attempts to run all your migrations. Then it invokes _dump which is an internal task for re-generating your schema.rb (or structure.sql) based on the latest DB schema changes.
Rails Database Migrations Best Practices
https://www.fastruby.io/blog/db-migrations-best-practices.htmlMeant to be deleted
I love this idea for a custom rake task (rails db:migrate:archive) to occasionally archive past migration files.
# lib/tasks/migration_archive.rake
namespace :db do
namespace :migrate do
desc 'Archives old DB migration files'
task :archive do
sh 'mkdir -p db/migrate/archive'
sh 'mv db/migrate/*.rb db/migrate/archive'
end
end
end
That way you still have access to them as development artifacts. Meanwhile you remove the migration clutter and communicate a reliance on the schema file for standing up fresh database instances (in dev/test/staging).
Data migrations
They don't go into much detail about data migrations. It's hard to prescribe a one-size-fits-all because sometimes the easiest thing to do is embed a bit of data manipulation in a standard schema migration, sometimes you want to manually run a SQL file against each database, or maybe you want to set up a process for these changes with a tool like the after_party gem.
Reversible migrations
For standard migrations, it is great to rely on the change method to ensure migrations are reversible. It's important to recognize what kinds of migrations are and aren't reversible. Sometimes we need to write some raw SQL and for that we are going to want up and down methods.
The ideal viewport doesn’t exist
https://viewports.fyi/There is a lot of interesting data in this article about the wide variations in viewport size. The particular thing that stuck out to me is that even for a single iPhone, you can easily have at least three different viewport sizes based on viewing context — Safari vs. in-app browser vs. 3D touch preview are the ones they show.
Found on Bluesky.
Keyboard shortcuts for Gmail
https://support.google.com/mail/answer/6594?sjid=3871484880356791029-NCI've been using gmail since something like 2006, but it never occurred to me to see if they have keyboard shortcuts or learn how to use them.
As a big-time vim user and fan of tools like vimium, I figure it is long overdue that I fix that. Note: if you want to try these, make sure you have Keyboard Shortcuts enabled from Gmail Settings.
Here are the shortcuts that I'm finding most useful at this point for how I use gmail today:
?to open a popover display of all shortcutsjandkto move down and up the threadlist of emails in my inboxeto archive the focused message#to delete the focused messagezto undo the last action (e.g. whoops, didn't mean to delete that message)
Some ones that I'm not using yet, but seem worth building some muscle memory around:
shift+tto make a task list item from the current message/conversationcmd+opt+,to send focus back to the inboxbto snooze a conversation
Parameter Type Inference - could not determine data type of parameter $1
https://github.com/adelsz/pgtyped/issues/354Odd PostgreSQL thing related to Prepared Statement / Parameter Type Inference I'm still trying to unravel.
I had the following bit of ActiveRecord query:
@tags =
Tag.where("? is null or normalized_value ilike ?", normalized_query, "%#{normalized_query}%")
.order(:normalized_value)
.limit(10)
which short-circuits the filter (where) if normalized_query is nil. This worked in development when the normalized_query value was and wasn't present.
However, as soon as I shipped this to production, it was failing. I found the following error in the logs:
Caused by: PG::IndeterminateDatatype (ERROR: could not determine data type of parameter $1)
I fixed it by rewriting the query to type cast to text which made postgres no longer unsure in production what the type of the parameter would be:
@tags =
Tag.where("cast(? as text) is null or normalized_value ilike ?", normalized_query, "%#{normalized_query}%")
.order(:normalized_value)
.limit(10)
Yay, fixed. Buuut, I don't get why this worked in dev, but not production. My best guesses are either that there is some different level of type inference that production is configured for (seems unlikely) or that the prepared statement in production gets prepared with different type info. Perhaps different connections are getting different prepared statement versions which might lead to it being flaky?
This is weird. Any idea what could be going on here?
Interestingly, I found a typescript project that was reporting the EXACT same issue for the EXACT same type of query -- https://github.com/adelsz/pgtyped/issues/354
Email Regexp is 23k
https://code.iamcal.com/php/rfc822/full_regexp.txtI prefer something dumber like /\S+@\S+\.\S+/, but I guess someone has to be thorough.
Shared by Sam Rose
Rails Controller Testing: `assigns()` and `assert_template()` removed in Rails 5
https://github.com/rails/rails/issues/18950Issue: Deprecate assigns() and assert_template in controller testing · Issue #18950 · rails/rails · GitHub
Testing what instance variables are set by your controller is a bad idea. That's grossly overstepping the boundaries of what the test should know about. You can test what cookies are set, what HTTP code is returned, how the view looks, or what mutations happened to the DB, but testing the innards of the controller is just not a good idea.
If you still want to be able to do this kind of thing in your controller or request specs, you can add the functionality back with rails-controller-testing.
You Probably Don't Need Query Builders
https://mattrighetti.com/2025/01/20/you-dont-need-sql-buildersthe tl;dr of this article is that you can avoid a bunch of ORM/query building and extraneous app logic by leaning on the expressiveness and capability of SQL.
The query building example in this post is a good illustration of why where 1 = 1 shows up in some SQL queries, usually in the logs from an ORM.
Interesting: one example uses Postgres' cardinality(some_array) = 0 to check if an array is empty or not. For one-dimensional array, cardinality is a bit more straightforward than array_length and requires only one argument.
Of further note, cardinality determines the number of items in an array regardless of how many dimensions an array is.
> select cardinality(array[1,2]);
+-------------+
| cardinality |
|-------------|
| 2 |
+-------------+
> select cardinality(array[[1,2], [3,4]]);
+-------------+
| cardinality |
|-------------|
| 4 |
+-------------+
> select cardinality(array[[[1,2,3], [4,5,6], [7,8,9]]]);
+-------------+
| cardinality |
|-------------|
| 9 |
+-------------+
Tampopo | IMDB
https://www.imdb.com/title/tt0092048/Recommended to me as a good, post-Fordism Japanese movie
The Cost of Going it Alone
https://blogs.gnome.org/bolsh/2011/09/01/the-cost-of-going-it-alone/A couple historical lessons learned about using, building on, and contributing to free (open source) software.
- The longer your changes are off the main branch, the harder and more expensive they are going to be to integrate. This is true of a feature branch on your own software project and of "out of tree" changes to a large open-source project like Linux.
- If a major dependency of your business is an open-source software project (e.g. Postgres, Ruby, Linux, etc.), you should probably be employing a contributor who has a strong relationship with that project. E.g. the various companies that have employed Aaron Patterson to work on Ruby.
Regarding the second bullet point, another common pattern now days is for open-source maintainers of important (but much smaller than, say, Linux-size) software projects to crowd-fund their work via GitHub sponsors from companies and individuals.
Shared by Jeremy Schneider on Linkedin.
Best place to learn to use PostgreSQL
https://www.reddit.com/r/PostgreSQL/comments/1i84wtv/best_place_to_learn_to_use_postgresql/A summary of the resources mentioned:
Speed matters: Why working quickly is more important than it seems
https://jsomers.net/blog/speed-mattersBeing able to do something quickly lowers the cognitive barrier to doing that thing more often.
This blog post is the best thing I've read "in defense of getting good at Vim". Sure, the learning curve is high and it can require a lot of configuration and memorization, but that is all in exchange for shrinking the time between thought and executing it on the computer.
The obvious benefit to working quickly is that you'll finish more stuff per unit time. But there's more to it than that. If you work quickly, the cost of doing something new will seem lower in your mind. So you'll be inclined to do more.
The general rule seems to be: systems which eat items quickly are fed more items. Slow systems starve.
When you're fast, you can quickly play with new ideas.
Part of the activation energy required to start any task comes from the picture you get in your head when you imagine doing it.
Complexity Has to Live Somewhere
https://ferd.ca/complexity-has-to-live-somewhere.html"Complexity has to live somewhere. If you are lucky, it lives in well-defined places... You give it a place without trying to hide all of it. You create ways to manage it. You know where to go to meet it when you need it."
It is useful for complexity to be abstracted away when it would otherwise detract from or complicate the task at hand. Then there are times where you need to interact with the complexity directly. These tasks will be best served by having a well-defined place where you know you can meet the complexity.
Regarding abstractions, I once heard something along the lines of, "a good abstraction is one that allows you to safely make assumptions about how something will work." In other words, with a good abstraction you don't have to reconfirm a litany of details, but can, for standard scenarios, make reasonable assumptions that save you time and mental overhead.
Putting it all together, good abstractions allow for beneficial assumptions, but when those assumptions aren't going to hold up, we ought to have a well-defined place to go wrangle with the complexity.
I came across this article while reading The Essence of Successful Abstractions — Sympolymathesy, by Chris Krycho.
Software lessons from Factorio
https://www.linkedin.com/posts/hillel-wayne_factorio-activity-7282805593428402176-xB8j/"Scalability and efficiency are fundamentally at odds. Software that maximizes the value of the provided resources will be much harder to scale up, and software that scales up well will necessarily be wasteful."
Moving on from React, a year later
https://kellysutton.com/2025/01/18/moving-on-from-react-a-year-later.html"One of the many ways this matters is through testing. Since switching away from React, I’ve noticed that much more of our application becomes reliably-testable. Our Capybara-powered system specs provide excellent integration coverage."
"When we view the lines of code as a liability, we arrive at the following operating model: What is the least amount of code we can write and maintain to deliver value to customers?"
Not all lines of code are equal, some cost more than others to write and to maintain ("carrying cost"). Some have a higher regression risk over time than others.
"When thinking about the carrying cost of different lines of code, maintaining different levels of robust tests reduces the maintenance fees I must pay. So, increasing my more-difficult-to-test lines of code is more expensive than increasing my easier-to-test lines of code."
Language, in as much as it relates to testability, is the metric of focus here. What other facets of code increase or decrease their "carrying cost"?
Good, Fast, Cheap: Pick 3 or Get None
https://loup-vaillant.fr/articles/good-fast-cheap"To get closer to the simplest solution, John Ousterhout recommends, you should design it twice. Try a couple different solutions, see which is simplest. Which by the way may help you think of another, even simpler solution."