AI (28 blogmarks)
← BlogmarksWater-use for data centers versus almonds
https://bsky.app/profile/mtsw.bsky.social/post/3mo22c3iirs2e"2.5 billion gallons" sounds like a lot but is about 2 tenths of 1% of the amount of water (approx 5 million acre-feet per year) used to grow almonds just in California.
This is in response to a report from Amazon that their global data-center operations withdrew 2.5 billion gallons of water in 2025.
Related: The AI Water Issue is Fake
Goblins, gremlins, and raccoons. Oh my!
https://bsky.app/profile/emollick.bsky.social/post/3mkjwmbebr22pExcerpt of a recent addition to the Codex for GPT-5.5 system prompt:
Never talk about goblins, gremlins, raccoons, trolls, ogres, pigeons, or other animals or creatures unless it is absolutely and unambiguously relevant to the user’s query.
Project Glasswing: Securing critical software for the AI era
https://www.anthropic.com/glasswingMythos Preview has already found thousands of high-severity vulnerabilities, including some in every major operating system and web browser. Given the rate of AI progress, it will not be long before such capabilities proliferate, potentially beyond actors who are committed to deploying them safely. The fallout—for economies, public safety, and national security—could be severe. Project Glasswing is an urgent attempt to put these capabilities to work for defensive purposes.
The People Do Not Yearn For Automation
https://www.theverge.com/podcast/917029/software-brain-ai-backlash-databases-automationThis article makes the case that AI doesn't have a marketing problem. Rather the AI companies are pushing "solutions" that people don't want into every system that they use day-to-day.
And so the tech industry is rushing forward to put AI everywhere at enormous cost — energy, emissions, manufacturing capacity, the ability to buy RAM — and locked into the narrow framework of software brain without realizing they are also asking people to be fundamentally less human. They then sit around wondering why everyone hates them.
This article talks about "Software Brain" a bunch which is a precursor (or precondition) of "AI Psychosis". If you think of everything in terms of how it can be flattened into software systems, then it's a short step to start thinking about how you can use AI all the time to 10x and automate all of that.
The 2025 AI Engineering Reading List
https://www.latent.space/p/2025-papersThe people at latent.space have curated a list of ~50 papers across ten areas for AI engineers looking to dig into relevant research in the AI and LLM space in 2025.
Here we curate “required reads” for the AI engineer. Our design goals are:
- pick ~50 papers (~one1 a week for a year), optional extras. Arbitrary constraint.
- tell you why this paper matters instead of just name drop without helpful context
- be very practical for the AI Engineer; no time wasted on Attention is All You Need, bc 1) everyone else already starts there, 2) most won’t really need it at work
Funny to see that they completely side-step "Attention is All You Need". As foundational as that paper is, they consider it old news and not practical for engineers in 2025.
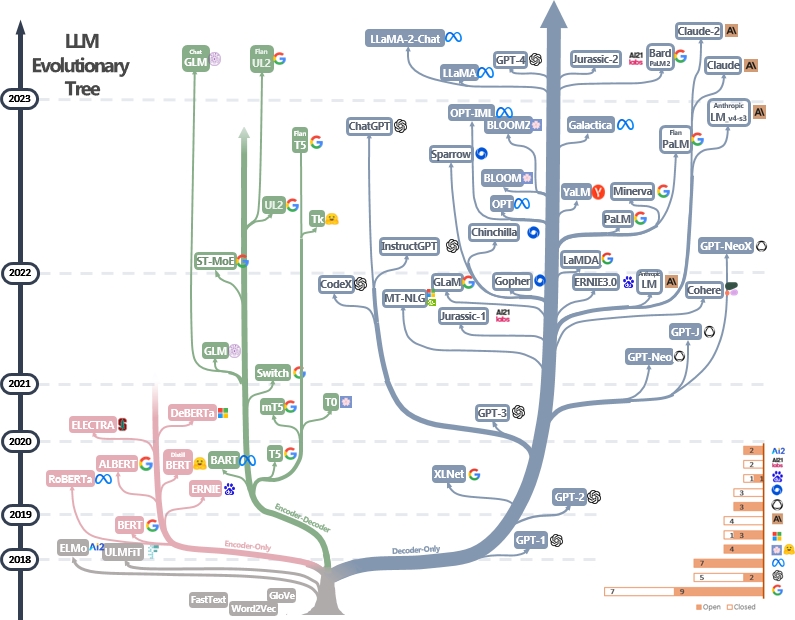
There is a repo LLM Practical Guide full of papers and an "LLM Tree" diagram that may have been a partial source of inspiration for the latent.space paper clubs. Unfortunately, this repo hasn't been updated since 2023. That said, there are still a lot of good resources in there.
This "LLM Tree" diagram is excellent showing the different branches of LLM tooling over time.
AI Psychosis
I'm seeing the term "AI Psychosis" pop up all over the place right now. Here are just a few places:
From Kill Chain, by Kevin Baker:
This obsession with Claude is a kind of AI psychosis, though not of the kind we normally talk about, and it afflicts critics and opponents of the technology as fiercely as it does its boosters. You do not have to use a language model to let it organize your attention or distort your thinking.
From a recent interview with Andrej Karpathy:
I kind of feel like I was in this perpetual, I still am often in this state of AI psychosis, just like all the time, because there was a huge unlock in what you can achieve as a person, as an individual, right? ... And so there's like a lot of new things. I want to be at the forefront of it, you know, and I'm very antsy that I'm not at the forefront of it. And I see lots of people on Twitter doing all kinds of things and they all sound like really good ideas. And I need to be at the forefront or I feel extremely nervous. And so I guess I'm just in the psychosis of like what's possible, like because it's unexplored fundamentally.
From Jasmine Sun's claude code psychosis:
I dubbed this phase my “Claude Code psychosis,” though some argue “mania” is the better term. It’s addictive to express a vision and see it instantly appear, getting into the build/test/iterate loop at an electrifying rate. There’s an apt joke that Claude Code is GPT-4o for nerds: it reflects your desires and makes them real, providing the rush of creation with minimal sweat.
Patricia Clarke compares the “Glass Delusion” to what is happening now with AI, also using the term “AI Psychosis”.
Aaron Levie (CEO of Box) posted the following on X which I pulled from Tech CEOs Are Apparently Suffering From AI Psychosis:
CEOs are uniquely prone to AI psychosis because they’re sufficiently distant from the last mile of work that still has to happen to generate most value with AI
Centaurs and Cyborgs on the Jagged Frontier
https://www.oneusefulthing.org/p/centaurs-and-cyborgs-on-the-jaggedAI is weird, there is no instruction manual
AI is weird. No one actually knows the full range of capabilities of the most advanced Large Language Models, like GPT-4. No one really knows the best ways to use them, or the conditions under which they fail. There is no instruction manual. On some tasks AI is immensely powerful, and on others it fails completely or subtly. And, unless you use AI a lot, you won’t know which is which.
Here are observations of lower-performers going from no-AI to using AI:
We also found something else interesting, an effect that is increasingly apparent in other studies of AI: it works as a skill leveler. The consultants who scored the worst when we assessed them at the start of the experiment had the biggest jump in their performance, 43%, when they got to use AI. The top consultants still got a boost, but less of one.
I’m not sure “skill leveler” is the right term here. Something like “speed-booster” or “efficiency enhancer” seems more apt to me. When I think about programmers using LLMs and agent harnesses, they aren’t usually writing a new level of code, but rather producing a similar quality of code at much faster speeds.
This paragraph from Mollick’s book “Co-Intelligence” sums up these concepts well:
Using Al as a co-intelligence, as I did while writing is where Al is the most valuable. Figure out a way to do this yourself if you can. As a starting point, follow the first principle (invite AI to everything) until you start to learn the shape of the Jagged Frontier in your work. This will let you know what the Al can do and what it can't. Then start working like a Centaur. Give the tasks that you hate but can easily check (like writing meaningless reports or low-priority emails) to the AI and see whether it improves your life. You will likely start to transition naturally into Cyborg usage, as you find the Al indispensable in overcoming small barriers and helping with tricky tasks. At that point, you have found a co-intelligence.
When Using AI Leads to “Brain Fry”
https://hbr.org/2026/03/when-using-ai-leads-to-brain-fryIn a recent HBR article AI Reduce Work – It Intensifies It, results of a study were shared that found that adoption of AI for work tasks gives way to both productivity gains and an intensification of the work to be done. That intensification leads to overwhelm and overwork characterized as "cognitive fatigue, burnout, and weakened decision-making."
In this more recent article from HBR, we see the results of another study that shows that certain patterns of AI use at work can lead to what they term AI Brain Fry.
AI promises to act as an amplifier that will drive efficiency and make work easier, but workers that are using these AI tools report that they are intensifying rather than simplifying work.
The authors differentiate it from burnout:
We call it “AI brain fry,” which we define as mental fatigue from excessive use or oversight of AI tools beyond one’s cognitive capacity. Participants described a “buzzing” feeling or a mental fog with difficulty focusing, slower decision-making, and headaches. This AI-associated mental strain carries significant costs in the form of increased employee errors, decision fatigue, and intention to quit.
In particular, they found that oversight as an AI engagement activity was the most mentally taxing. And second to that is the degree to which the use of AI tools has led to internal or external pressure to get more done in the same amount of time.
These two factors together—AI oversight and an increase in workload—increase an employee’s sphere of accountability, requiring them to pay attention to more outcomes for more tools in the same amount of time. It makes sense that cognitive load increased, and with it, their mental exhaustion.
There is a lot more in this article, including the idea that use of three simultaneous AI tools is the magic number and when you go to four, the productivity scores dip.
I heard about this article from the latest episode of the Hard Fork podcast – A.I. Goes to War + Is ‘A.I. Brain Fry’ Real? + How Grammarly Stole Casey’s Identity
November 2025 Inflection
https://simonwillison.net/tags/november-2025-inflection/I've seen a lot of heads turn in the months since Opus 4.5 and GPT 5.1 were released. A lot of software developers going from "I use LLMs occassionaly" to "these models are good enough to use all the time."
As Simon Willison pointed out, this feels like a major inflection point in both the capabilities and adoption of LLMs:
November 2025 felt like an inflection point for coding agents, with Opus 4.5 and GPT 5.1 (and GPT-5.1 Codex) increasing the utility of those agents in a very noticeable way.
AI Doesn’t Reduce Work—It Intensifies It
https://hbr.org/2026/02/ai-doesnt-reduce-work-it-intensifies-itThis 8-month study of 200 employees found that these employees used AI tools to work at a faster pace and take on a broader scope of work.
While this may sound like a dream come true for leaders, the changes brought about by enthusiastic AI adoption can be unsustainable, causing problems down the line. Once the excitement of experimenting fades, workers can find that their workload has quietly grown and feel stretched from juggling everything that’s suddenly on their plate. That workload creep can in turn lead to cognitive fatigue, burnout, and weakened decision-making.
Crucially,
The productivity surge enjoyed at the beginning can give way to lower quality work, turnover, and other problems.
This all rings pretty true to my own experience. I am definitely finding that I'm able to get more done with these tools, but that is, in part, because I've convinced myself that I can take on extra work because of the upfront time savings.
It is an ongoing challenge to explore how to balance all of it.
The findings from this study seem consistent with what happened with factory automation in the 20th century. Instead of reducing the workload, automation intensified the work, made it more repetitive, and increased the chance of injury. The physical stakes of AI's introduction to knowledge work is much different, but the parallels are there.
Build a Large Language Model (From Scratch) - Sebastian Raschka
https://www.manning.com/books/build-a-large-language-model-from-scratchA lot of examples used when building up the concepts behind LLMs use vectors somewhere in the range of 2 to 10 dimensions. The dimensionality of real-world models is much higher:
The smallest GPT-2 models (117M and 125M parameters) use an embedding size of 768 dimensions... The largest GPT-3 model (175B parameters) uses an embedding size of 12,288 dimensions.
The Self-Attention Mechanism:
A key component of transformers and LLMs is the self-attention mechanism, which allows the model to weigh the importance of different words or tokens in a sequence relative to each other. This mechanism enables the model to capture long-range dependencies and contextual relationships within the input data, enhancing its ability to generate coherent and contextually relevant output.
Variants of the transformer architecture:
- BERT (Bidirectional Encoder Representations from Transformers) - "designed to pre-train deep bidirectional representations from unlabeled text by jointly conditioning on both left and right context in all layers."
- GPT (Generative Pretrained Transformers) - "primarily designed and trained to perform text completion tasks."
BERT receives input where some words are missing and then attempts to predict the most likely word to fill each of those blanks. The original text can then be used to provide feedback to the model's predictions during training.
GPT models are pretrained using self-supervised learning on next-word prediction tasks.
Foundation models are called that because the are generalized with their pretraining and can then be fine-tuned afterward to specific tasks.
How To Not Be Replaced by AI
https://www.maxberry.ca/p/how-to-not-be-replaced-by-aiYou don’t compete with AI.
You amplify yourself with it.
You become the expert who knows when to trust the machine and when to override it.
The market will pay a premium for people who can be trusted with high-stakes decisions, not people who can produce high volumes of low-stakes work.
Security beyond the model: Introducing AI system cards
https://www.redhat.com/en/blog/security-beyond-model-introducing-ai-system-cardsIn practice, end users engage with systems, not raw models, which is why a single foundational model can power hundreds of tailored solutions across domains. Without the surrounding infrastructure of an AI system, even the most advanced model remains untapped potential rather than a tool that solves real‑world problems.
I don’t want AI agents controlling my laptop – Sophie Alpert
https://sophiebits.com/2025/09/09/ai-agents-securityThere’s no good way to say “allow access to everything on my computer, except for my password manager, my bank, my ~/.aws/credentials file, and the API keys I left in my environment variables”. Especially with Simon Willison’s lethal trifecta, you don’t really want to be giving access to these things, even if most of the time, nothing bad happens.
What Happened When I Tried to Replace Myself with ChatGPT in My English Classroom
https://lithub.com/what-happened-when-i-tried-to-replace-myself-with-chatgpt-in-my-english-classroom/Like many teachers at every level of education, I have spent the past two years trying to wrap my head around the question of generative AI in my English classroom. To my thinking, this is a question that ought to concern all people who like to read and write, not just teachers and their students.
Each student submitted a draft of writing on a common subject and when the teacher presented all the titles in aggregate, you could see a plagiaristic convergence.
I expected them to laugh, but they sat in silence. When they did finally speak, I am happy to say that it bothered them. They didn’t like hearing how their AI-generated submissions, in which they’d clearly felt some personal stake, amounted to a big bowl of bland, flavorless word salad.
Via conputer dipshit
How I keep up with AI progress
http://blog.nilenso.com/blog/2025/06/23/how-i-keep-up-with-ai-progress/To help with this, I’ve curated a list of sources that make up an information pipeline that I consider balanced and healthy. If you’re late to the game, consider this a good starting point.
Their top recommendation of what to follow if you were to only follow one thing is the same as mine — Simon Willison’s blog.
But don’t stop there, this article is jam packed with links to other people and resources in the AI and LLM space.
AI didn’t kill Stack Overflow
https://www.infoworld.com/article/3993482/ai-didnt-kill-stack-overflow.htmlFor Stack Overflow, the new model, along with highly subjective ideas of “quality” opened the gates to a kind of Stanford Prison Experiment. Rather than encouraging a wide range of interactions and behaviors, moderators earned reputation by culling interactions they deemed irrelevant. Suddenly, Stack Overflow wasn’t a place to go and feel like you were part of a long-lived developer culture. Instead, it became an arena where you had to prove yourself over and over again.
This reminded me of a comment that a friend made to me about StackOverflow. Notably, he has been on the tough end of over-eager moderation.
I do think that the moderation changes were bad. I don't know what problems they were trying to solve, or if it worked. But I watched so many good-faith questions and answers get absolutely smacked down by the moderators… Not how I think beginners should be treated.
Related: StackOverflow is Almost Dead
I am disappointed in the AI discourse
https://steveklabnik.com/writing/i-am-disappointed-in-the-ai-discourse/It’s more that both the pro-AI and anti-AI sides are loudly proclaiming things that are pretty trivially verifiable as not true. On the anti side, you have things like the above. And on the pro side, you have people talking about how no human is going to be programming in 2026. Both of these things fail a very basic test of [is it true?].
There is no Vibe Engineering
https://serce.me/posts/2025-31-03-there-is-no-vibe-engineeringSoftware engineering is programming integrated over time. The integrated over time part is crucial. It highlights that software engineering isn't simply writing a functioning program but building a system that successfully serves the needs, can scale to the demand, and is able to evolve over its complete lifespan.
LLMs generate point-in-time code artifacts. This is only a small part of engineering software systems over time.
Vibe Coding as a practice is here to stay. It works, and it solves real-world problems – getting you from zero to a working prototype in hours. Yet, at the moment, it isn’t suitable for building production-grade software.
The 70% problem: Hard truths about AI-assisted coding
https://addyo.substack.com/p/the-70-problem-hard-truths-aboutLLMs are no substitute for the hard-won expertise of years of building software, working within software teams, and evolving systems. You can squeeze the most out of iterations with a coding LLM by bringing that experience to every step of the conversation.
In other words, they're applying years of hard-won engineering wisdom to shape and constrain the AI's output. The AI is accelerating their implementation, but their expertise is what keeps the code maintainable.
The 70% problem
A tweet that recently caught my eye perfectly captures what I've been observing in the field: Non-engineers using AI for coding find themselves hitting a frustrating wall. They can get 70% of the way there surprisingly quickly, but that final 30% becomes an exercise in diminishing returns.
Addy goes on to describe this "two steps back pattern" where a developer using an LLM encounters an error, they ask the LLM to suggest a fix, the fix sorta works but two other issues crop up, and repeat.
This cycle is particularly painful for non-engineers because they lack the mental models to understand what's actually going wrong. When an experienced developer encounters a bug, they can reason about potential causes and solutions based on years of pattern recognition.
Beyond having the general programming and debugging experience to expedite this cycle, there is also an LLM intuition to be developed. I remember John Lindquist describing that he notices certain "smells" when working with LLMs. For instance, often when you're a couple steps into a debugging cycle with an LLM and it starts wanting to go make changes to config files, that is a smell. It's a "smell" because it should catch your attention and scrutiny. A lot of times this means the LLM is way off course and it is now throwing generative spaghetti at the wall. I learned two useful things from John through this:
- You have to spend a lot of time using different models and LLM tools to build up your intuition for these "smells".
- When you notice one of these smells, it's likely that the LLM doesn't have enough or the right context. Abort the conversation, refine the context and prompt, and try again. Or feed what you've tried into another model (perhaps a more powerful reasoning one) and see where that gets you.
Being able to do any of that generally hinges on having already spent many, many years debugging software and having already developed some intuitions for what is a good next step and what is likely heading toward a dead end.
These LLM tools have shown to be super impressive at specific tasks, so it is tempting to generalize their utility to all of software engineering. However, at least for now, we should recognize the specific things they are good at and use them for that:
This "70% problem" suggests that current AI coding tools are best viewed as:
- Prototyping accelerators for experienced developers
- Learning aids for those committed to understanding development
- MVP generators for validating ideas quickly
I'd at to this list:
- Apply context-aware boilerplate autocomplete — establish a pattern in a file/codebase or rely on existing library conventions and a tool like Cursor will often suggest an autocompletion that saves a bunch of tedious typing.
- Scaffold narrow feature slices in a high-convention framework or library — Rails codebases are a great example of this where the ecosystem has developed strong conventions that span files and directories. The LLM can generate 90% of what is needed, following those conventions. By providing specific rules about how you develop in that ecosystem and a tightly defined feature prompt, the LLM will produce a small diff of changes that you can quickly assess and test for correctness. To me this is distinct from the prototyping item suggested by Addy because it is a pattern for working in an existing codebase.
Now you don’t even need code to be a programmer. But you do still need expertise
https://www.theguardian.com/technology/2025/mar/16/ai-software-coding-programmer-expertise-jobs-threatThis quote about Simon is spot on and it is why I recommend his blog whenever I talk to another developer who is worried about LLM/AI advancement.
A leading light in this area is Simon Willison, an uber-geek who has been thinking and experimenting with LLMs ever since their appearance, and has become an indispensable guide for informed analysis of the technology. He has been working with AI co-pilots for ever, and his website is a mine of insights on what he has learned on the way. His detailed guide to how he uses LLMs to help him write code should be required reading for anyone seeking to use the technology as a way of augmenting their own capabilities. And he regularly comes up with fresh perspectives on some of the tired tropes that litter the discourse about AI at the moment.
It is tough to wade through both the hype and the doom while trying to keep tabs on "the latest in AI". Simon has an excitement for this stuff, but it is always balanced, realistic, and thoughtful.
The author then goes on to quote Tim O'Reilly on the subject of "what does this mean for programming jobs?"
As Tim O’Reilly, the veteran observer of the technology industry, puts it, AI will not replace programmers, but it will transform their jobs.
Which compliments the sentiment from Laurie Voss' latest post AI's effects on programming jobs which expects we will see a lot more programming jobs in the wake of an LLM transformation of the industry.
And as my friend Eric suggested, the Jevons Paradox may come in to play where programmers are the "resource" being more efficiently consumed which will, paradoxically, increase the demand for programmers.
AI's effects on programming jobs
https://seldo.com/posts/ai-effect-on-programming-jobsI would like to advance a third option, which is that AI will create many, many more programmers, and new programming jobs will look different.
What do we call the emerging type of programming job where a person is instructing or orchestrating AIs and LLMs to do work while not necessarily knowing the lower level details (code)?
Including "AI" in the name feels wrong though, it's got a horseless carriage feel. All programming will involve AI, so including it in the name will be redundant.
The statement “All programming will include AI.” caught me attention. It seems like an optional, even niche tool at the moment. The prediction here being that it will become ubiquitous, perhaps to the same degree as using an IDE or to using auto code formatters.
I find myself and lots of others pondering on the impact of LLMs on software development to want to generalize to one big brush stroke, but I think the reality is going to be closer to what is described here.
I think we will see all three at the same time. Some AI-assisted software development will raise the bar for quality to previously cost-ineffective heights. Some AI-driven software will be the bare minimum, put together by people who could never have successfully written software before. And a great deal will be software of roughly the quality we see already, produced in less time, and in correspondingly greater quantity.
The general sentiment of this post is that there will be more jobs, not fewer. And that the impact on salaries (existing ones at least) won’t be much.
Some words of caution though:
But the adjustment won't be without pain: some shitty software will get shipped before we figure out how to put guardrails around AI-driven development. Some programmers who are currently shipping mediocre software will find themselves replaced by newer, faster, AI-assisted developers before they manage to learn AI tools themselves. Everyone will have a lot of learning to do. But what else is new? Software development has always evolved rapidly. Embrace change, and you'll be fine.
Via Seldo on Bluesky
Claude 3.7 Sonnet and Claude Code \ Anthropic
https://www.anthropic.com/news/claude-3-7-sonnetAn AI coding tool that I use directly from the terminal?! 👀
Claude Code is available as a limited research preview, and enables developers to delegate substantial engineering tasks to Claude directly from their terminal.
"thinking tokens"? Does that mean the input and output tokens that are used as part of intermediate, step-by-step "reasoning"?
In both standard and extended thinking modes, Claude 3.7 Sonnet has the same price as its predecessors: $3 per million input tokens and $15 per million output tokens—which includes thinking tokens.
The Claude Code Overview shows how to get started installing and using Claude Code in the terminal.
They all use it, by Thorsten Ball
https://registerspill.thorstenball.com/p/they-all-use-itMostly online, but in an occasional real-world conversation someone will be expressing their disinterest and dissatisfaction with LLMs in the realm of software development and they'll say, "I tried it and it just made stuff up. I don't trust it. It will take me less time to build it myself than fix all its mistakes."
My immediate follow-up question is usually "what model / LLM tool did you use and when?" because the answer is often GitHub copilot or some free-tier model from years ago.
But what I want to do is step back here like Thorsten and ask, "Aren't you curious? Don't you want to know how these tools fit into what we do and how they might start to reshape our work?"
What I don’t get it is how you can be a programmer in the year twenty twenty-four and not be the tiniest bit curious about a technology that’s said to be fundamentally changing how we’ll program in the future. Absolutely, yes, that claim sounds ridiculous — but don’t you want to see for yourself?
The job requires constant curiosity, relearning, trying new techniques, adjusting mental models, and so on.
What I’m saying is that ever since I got into programming I’ve assumed that one shared trait between programmers was curiosity, a willingness to learn, and that our maxim is that we can’t ever stop learning, because what we’re doing is constantly changing beneath our fingers and if we don’t pay attention it might slip aways from us, leaving us with knowledge that’s no longer useful.
I suspect much of the disinterest is a reaction to the (toxic) hype around all things AI. There is too much to learn and try for me to let the grifters dissuade me from the entire umbrella of AI and LLMs. I make an effort to try out models from all the major companies in the space, to see how they can integrate into the work I do, how things like Cursor can augment my day-to-day, discussing with others what workflows, techniques, prompts, strategies, etc. can lead to better, exciting, interesting, mind-blowing results.
I certainly don't think the writing is on the wall for all this GenAI stuff, but it feels oddly incurious if not negligent to simply write it off.
The Empty Promise of AI-Generated Creativity
https://hey.paris/posts/genai/This isn’t merely a technical limitation to be overcome with more data or better algorithms. It’s a fundamental issue: AI systems lack lived experience, cultural understanding, and authentic purpose—all essential elements of meaningful creative work. When humans craft stories, they draw upon personal struggles, cultural tensions, and genuine emotions. AI simply cannot access these wellsprings of authentic creation.
AI haters build tarpits to trap and trick AI scrapers that ignore robots.txt
https://arstechnica.com/tech-policy/2025/01/ai-haters-build-tarpits-to-trap-and-trick-ai-scrapers-that-ignore-robots-txt/Fascinating!
Aaron clearly warns users that Nepenthes is aggressive malware. It's not to be deployed by site owners uncomfortable with trapping AI crawlers and sending them down an "infinite maze" of static files with no exit links, where they "get stuck" and "thrash around" for months, he tells users. Once trapped, the crawlers can be fed gibberish data, aka Markov babble, which is designed to poison AI models.
I imagine the basic idea is to have a page that a crawler would find if it ignored your robots.txt. It would be served with nonsense content and tons of internal dynamic links which go to more pages full of nonsense content and tons more internal dynamic links. Less of a maze and more of a never-ending tree.
But efforts to poison AI or waste AI resources don't just mess with the tech industry. Governments globally are seeking to leverage AI to solve societal problems, and attacks on AI's resilience seemingly threaten to disrupt that progress.
Weird to make this unqualified claim with no examples of how governments are trying to solve societal problems with AI -- I'm certainly having a hard time thinking of any.
Edit: Cloudflare has since launched something similar that it calls an AI Labyrinth.
When AI crawlers follow these links, they waste valuable computational resources processing irrelevant content rather than extracting your legitimate website data. This significantly reduces their ability to gather enough useful information to train their models effectively.
My LLM codegen workflow atm
https://harper.blog/2025/02/16/my-llm-codegen-workflow-atm/Flip the script by getting the Conversational LLM to ask you questions instead of you asking it questions.
Ask me one question at a time so we can develop a thorough, step-by-step
spec for this idea. Each question should build on my previous answers, and
our end goal is to have a detailed specification I can hand off to a
developer. Let’s do this iteratively and dig into every relevant detail.
Remember, only one question at a time.Here’s the idea:
...
This is a good way to hone an idea, rubberduck, and think through a problem space.
I tried a session of this with Claude Sonnet 3.7. It asked a lot of good questions and got me thinking. After maybe 8 or so questions I ran into the warning from Claude about the conversation getting too long and running into usage limits (not sure what to do about that speed bump yet).
CONVENTIONS.md file for AI Rails 8 development
https://gist.github.com/peterc/214aab5c6d783563acbc2a9425e5e866Peter Cooper put together this file of conventions that a tool like Cursor or Aider should follow when doing Rails 8 development.
One issue that I constantly run into with Cursor is that it creates a migration file that is literally named something like db/migrate/[timestamp]_add_users_table.rb, instead of suggesting/running the migration generator command provided by Rails. I'm curious if there is a way to effectively get these tools to follow that workflow -- generate the file with rails g ... and then inject that file with the migration code.
Use Rails' built-in generators for models, controllers, and migrations to enforce Rails standards.
Maybe that rule is enough to convince Cursor to use the generator.