Blogmark
Tiktokenizer: visualize LLM prompt tokenization
via jbranchaud@gmail.com
https://tiktokenizer.vercel.app/
Using OpenAI's BPE tokenizer (tiktoken), this app shows a visualization of how different models will tokenize prompts (system and user input). If you've wondered what it means that a model has a 100k token context window, these are the tokens that are being counted.
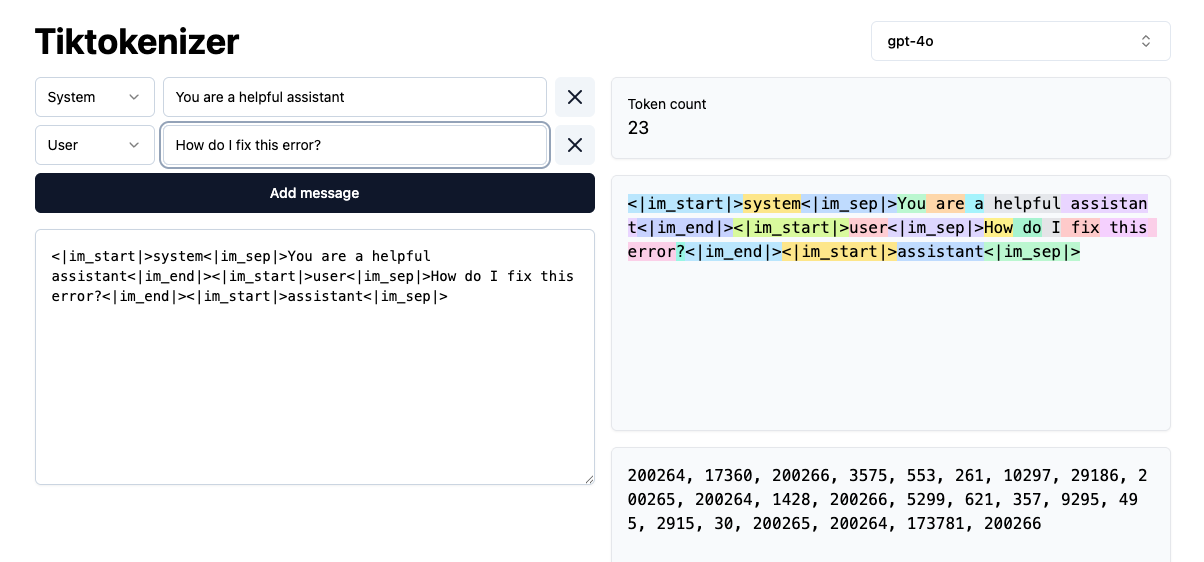
They vary from model to model because each model is using different vocabulary sizes as they try to optimize for their training corpus and overall inference capabilities. A smaller vocab size means smaller tokens which can be limiting for how "smart" the model can be. Larger vocab sizes can be an unlock for inference, but comes with a higher training cost and perhaps slower or more computationally expensive generation.